
Serialization REVOLUTION OR REGRESSION?
Comparing the Reference Architecture libraries to the best
In previous parts of this series, I investigated the performance of select serialization libraries in Java– including Google Gson, FasterXML Jackson, Java’s built-in serialization, Apache Johnzon, and Esoteric Software’s Kryo. From that investigation, I defined the core requirements of a new Serialization API in terms of speed, leanness, and quality. I dove deep into the selected libraries and compared their architectures for these qualities. From my archaeological work, I derived a common Reference Architecture for Serialization. I then implemented the reference architecture with two approaches, one following the JavaIO style and one following the other libraries. Now, I evaluate them against the available offerings.
Is what I built any good?
First, it’s only fair to evaluate the libraries using the same methodology as the others. So I put my JavaIO inspired library, which I call Streams, and my FACADE/STRATEGY library, which I call Loial, to the test. I’ll go in order of perceived importance: performance, quality, leanness.
Performance
Integration
One of the important user stories for the benchmarking project was:
The project should enable investigators to simply modify the experiment itself– such as adding different model data classes or integrating a new serialization framework for analysisI can confidently say I achieved that. Integration was straightforward. Simply implementing
SerializationFramework with a Loial and a Streams implementation and wiring things up was trivial.
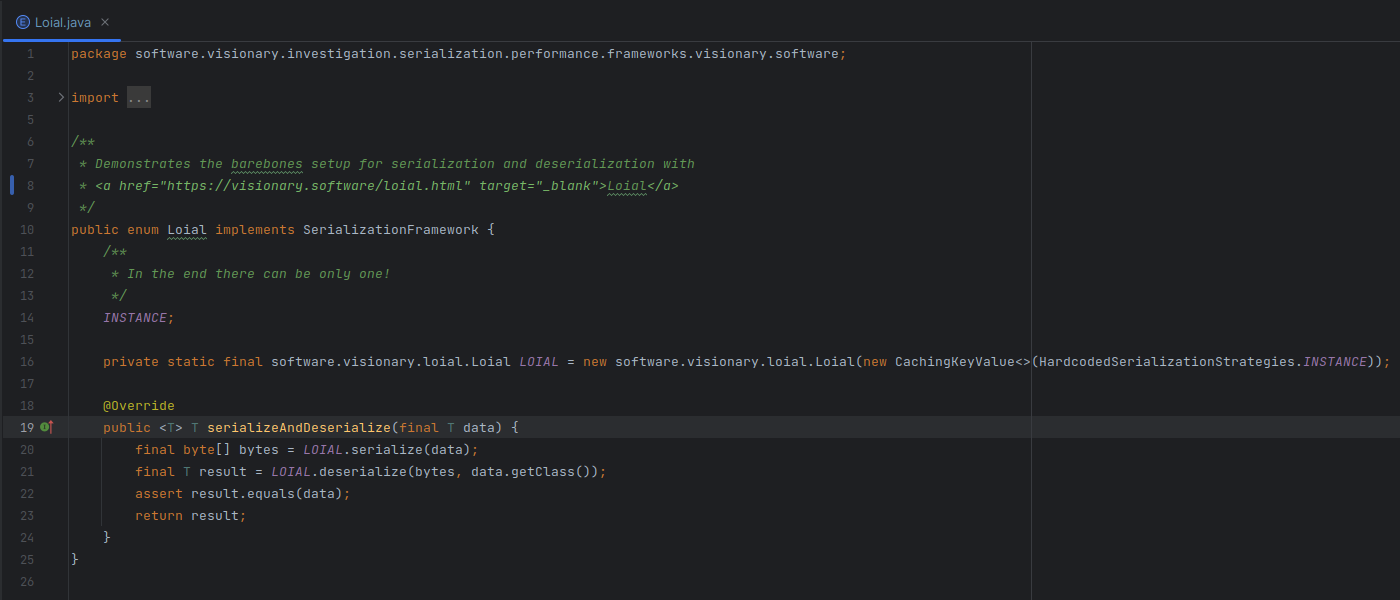
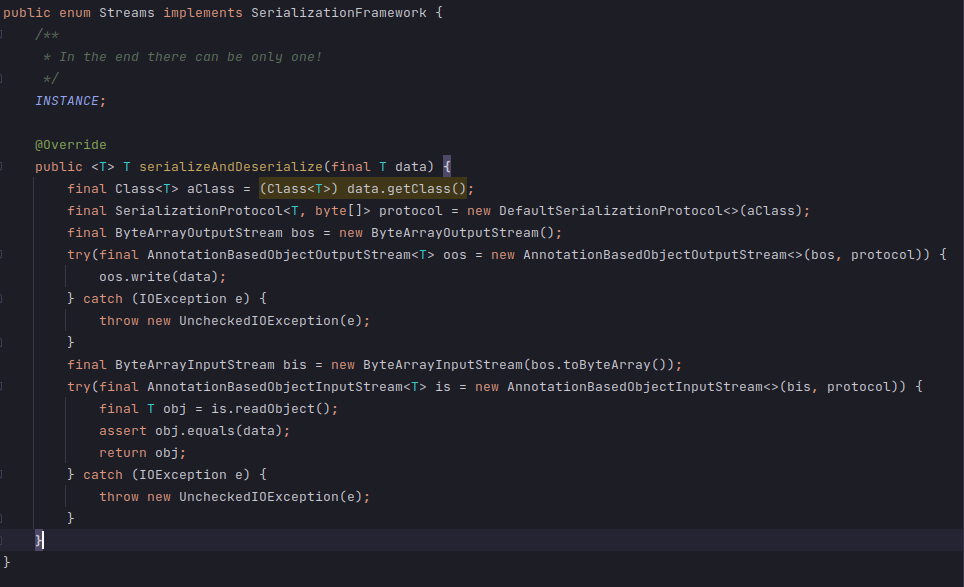
These frameworks are different from others in that they require the definition of a SerializationStrategy. One could argue that this makes them less functional than frameworks like Jackson/Kryo, which provide default serialization formats. I’m not convinced that is something serialization frameworks should offer by default.
Following the advice of Bloch from Effective Java and Goetz and Marks in subsequent analysis on serialization, serialization format design should be part of the object design process for serializable objects. The software industry has seen both a promulgation and widespread migrations from different formats since the 1980s–custom binary,XML,JSON,YAML,ProtocolBuffers, EDN– with no end in sight. Perhaps it is healthier for the overall state of the industry to push developers to think about serialization as a two-part concern–rather than something that “comes for free.”
Moreover, the framework architecture readily supports the development of plugins to emit objects in different formats. A variety of different approaches can be explored, including the common reflection based approach or code generation. In future work, I will explore using Annotation Processing to generate SerializationStrategy implementations for JSON and YAML.
Results
# of Objects of SingleBooleanClass
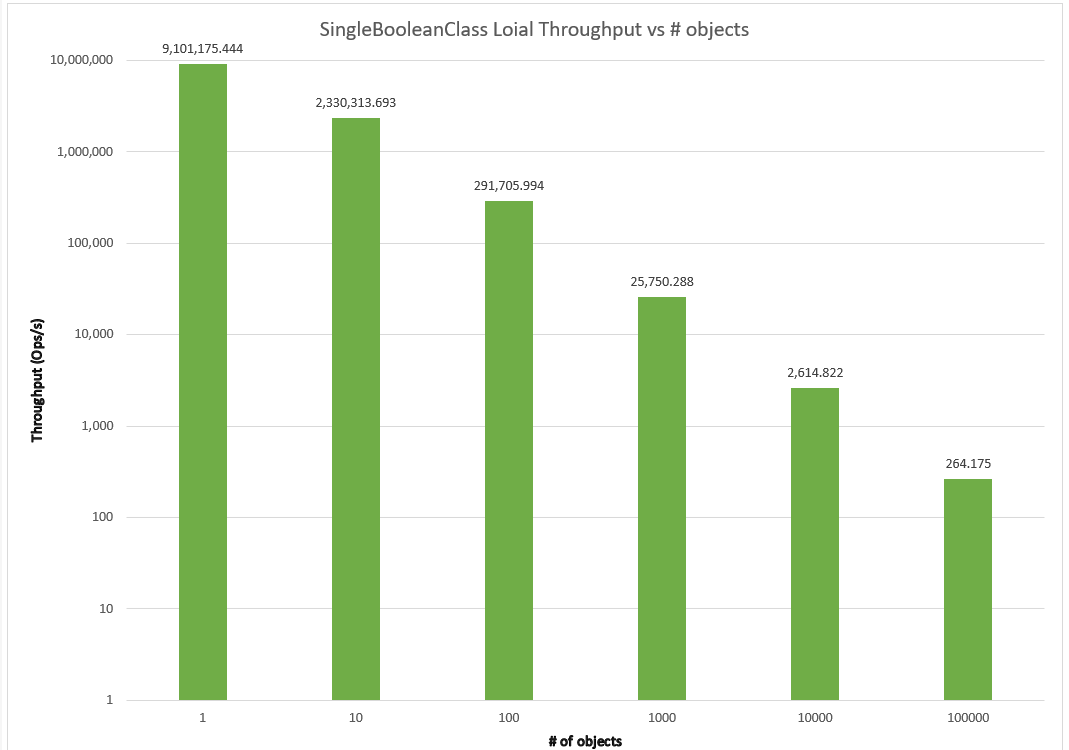
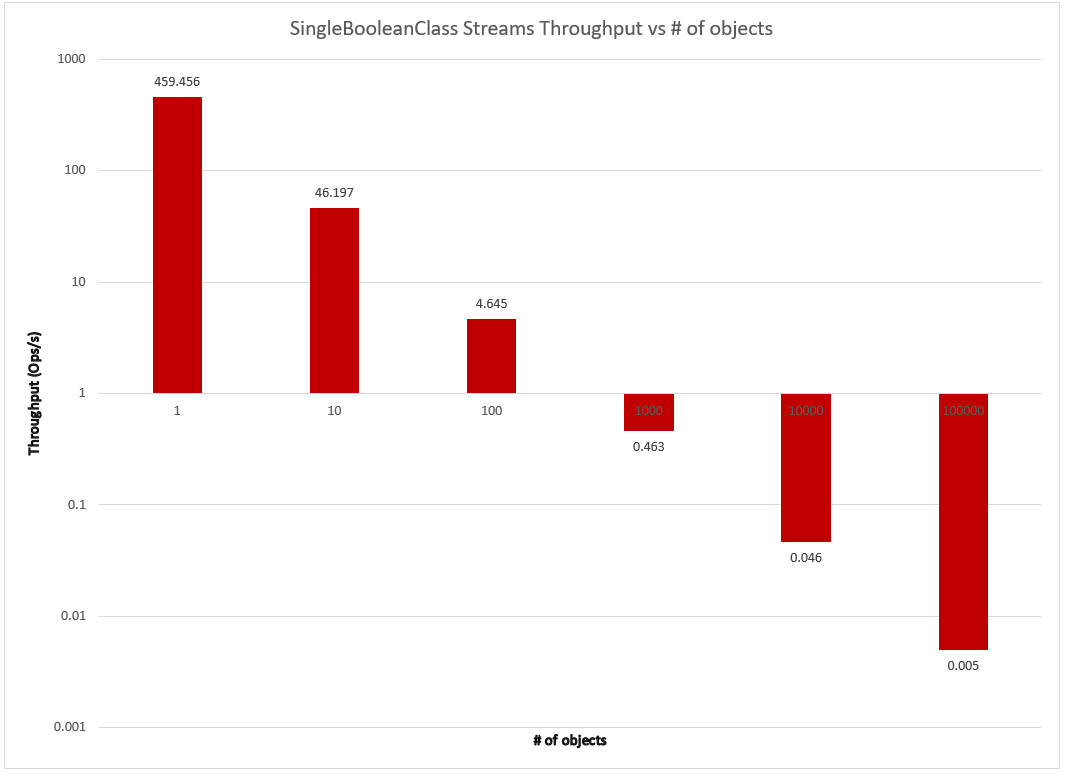
I could already see a remarkable difference between Streams and Loial. Looking at the garbage collector profile, it seemed Streams was generating much more garbage and spending much more time in garbage collection. Yet Java IO is also slow but actually has a better looking garbage collection profile–amongst the lowest in GC allocation rate, GC churn, GC counts and time– than many of the faster serialization frameworks. I’ve concluded that the bottleneck is actually the java.io.InputStream/java.io.OutputStream abstractions themselves. This makes intuitive sense, as Java developed NIO as a modernization of IO after identifying performance problems. The difference became even more glaring when compared with available libraries.
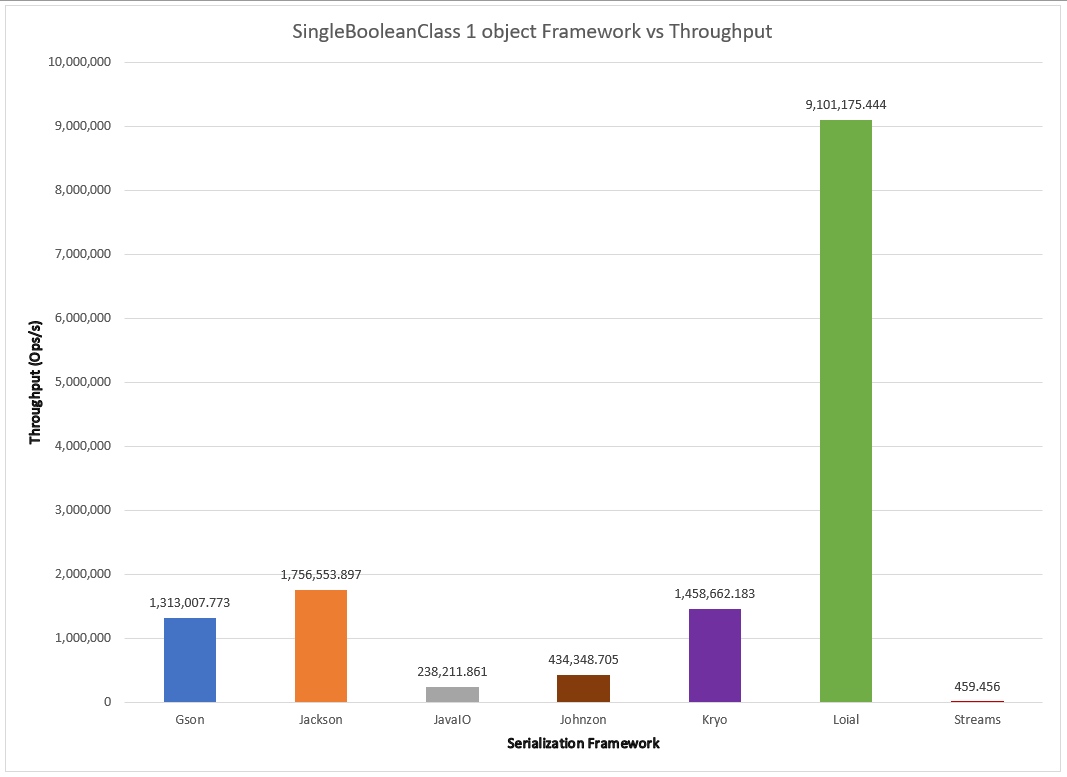
Number of fields: Comparing 1000 instances of SingleBooleanClass, TwoBooleanClass, ThreeBooleanClass
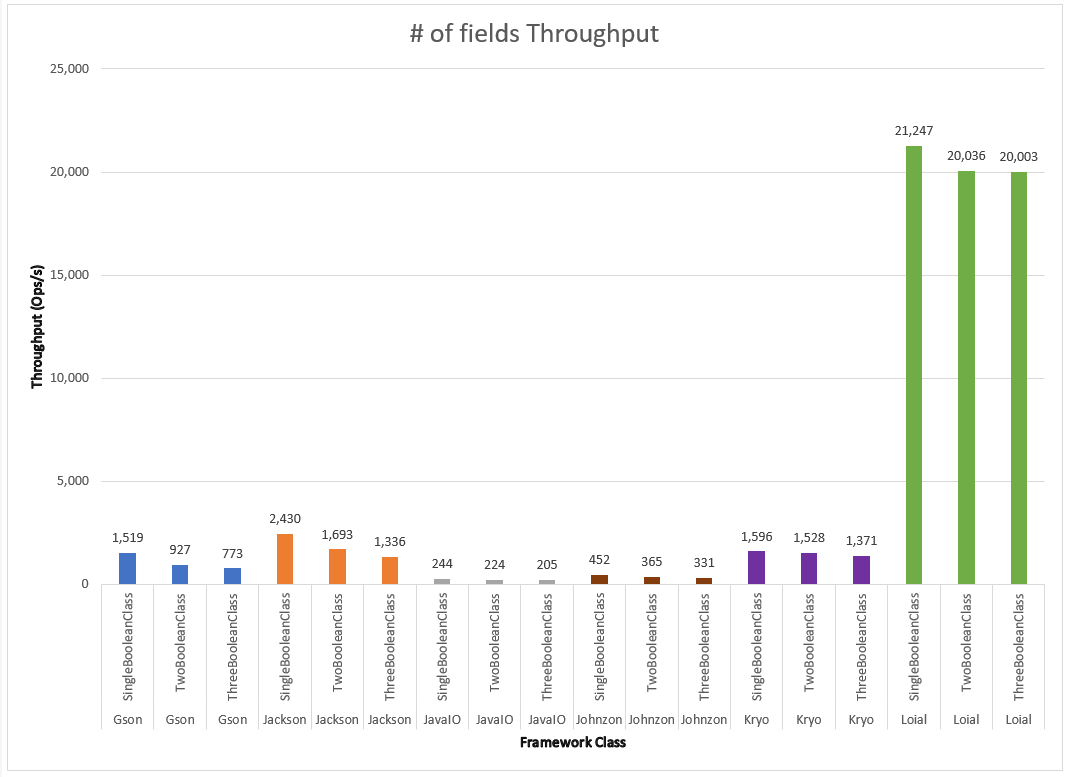
In the most optimistic case, Loial performed 9x better than Kryo and Jackson while Streams was 10x slower than Johnzon. Loial continued performing well for TwoBooleanClass and ThreeBooleanClass.
Number of objects with different types of fields
I decided to explore the frameworks at all instance counts–in case any “in # of fields > 3 Kryo starts being better than Jackson” type of effects occurred. I present the agglomerated throughput for ThreeFieldClass, FiveFieldClass, and TenFieldClass on single graphs to save space, with clustered bars for different number of objects thresholds, on a logarithmic scale to better visualize the obvious throughput differences between n={1,10,100,1000,10,000,100,000} objects. A careful reader will notice that Streams doesn’t appear at all in some of the graphs. For some benchmark runs JMH produced no data at all, leading me to believe that some kind of fatal condition occurred and caused the framework to crash.
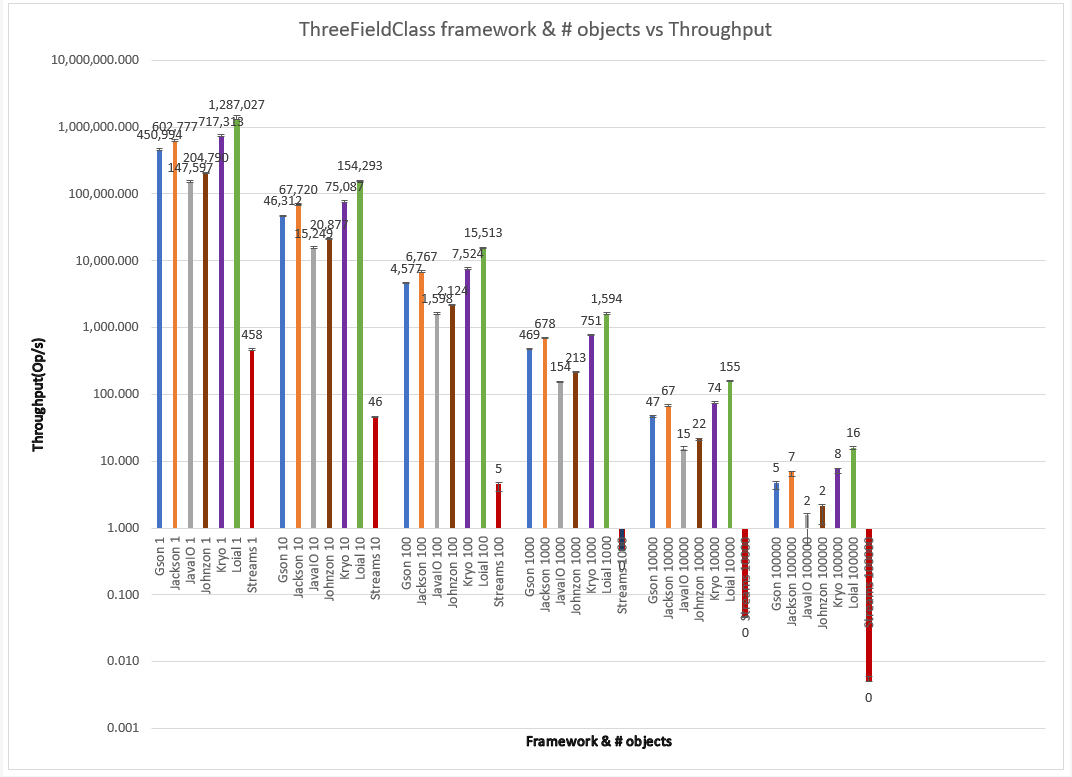
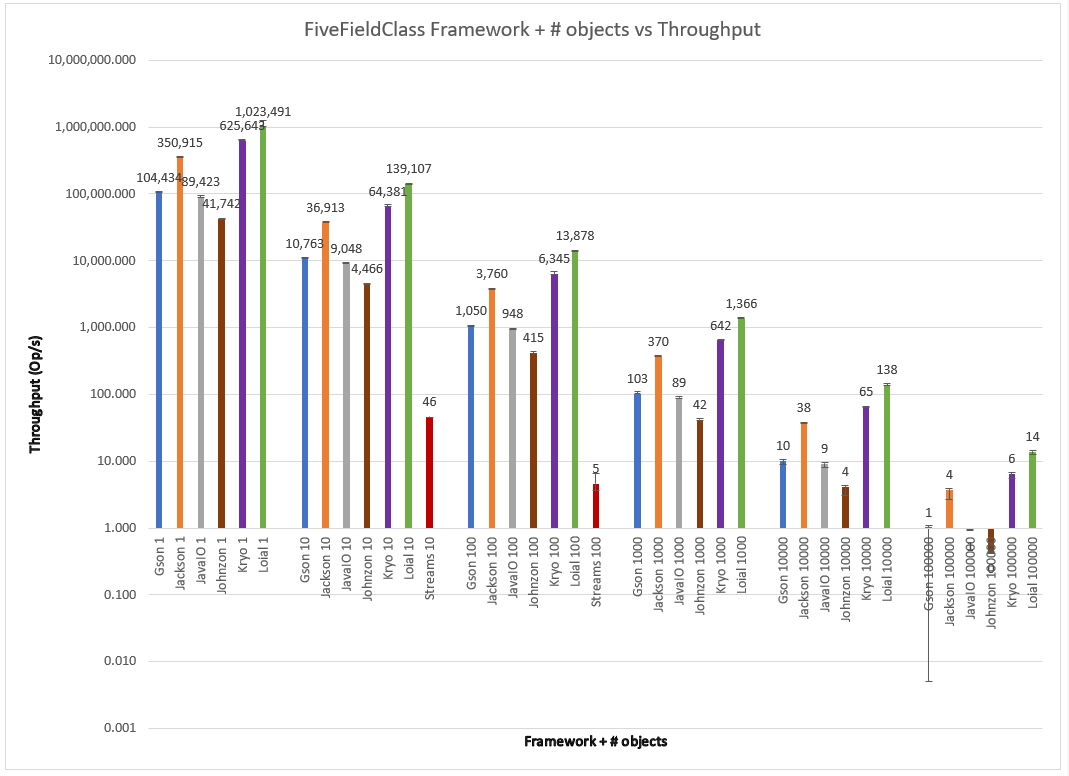
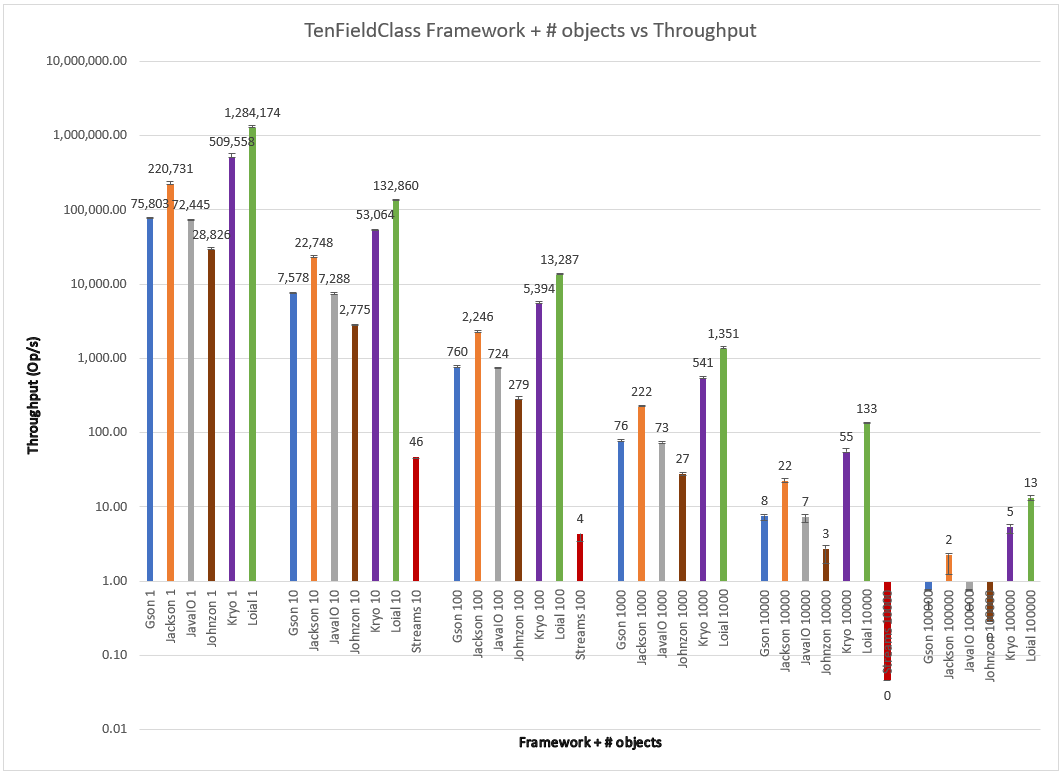
Loial consistently outperforms all other offerings by a wide margin across field count and number of instances. Probably the most important differences are for 100K objects of five and 10 fields. This kind of scale is common for successful web services like those found in AWS.
Here Loial gives almost 3x+ throughput than Jackson and 2x+ from Kryo for FiveFieldClass, 6x+ and 2x+ for TenFieldClass. This isn't necessarily applicable to a single smoking gun, like garbage collection. Rather it is due to a combination of factors. Loial was built to be minimal but flexible, these factors are not antithetical to performance.
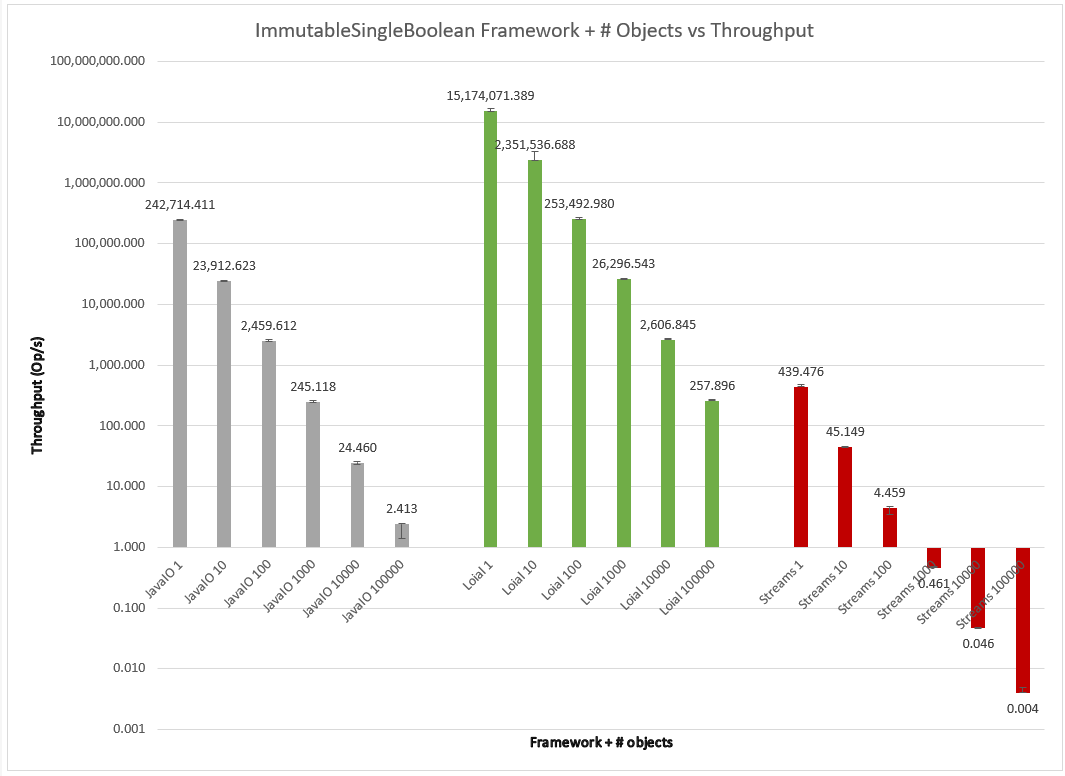
Immutability
As we remember, only Java IO supported immutable objects by default. Loial offers a performant alternative in this area. I also included Streams in the analysis, perhaps showing how a naive approach towards implementing Java IO style serialization leads to some of the complexity of Caches and HandleTables that one finds in the OpenJDK java.io.ObjectInputStream/java.io.ObjectOutputStream.
Garbage Collection
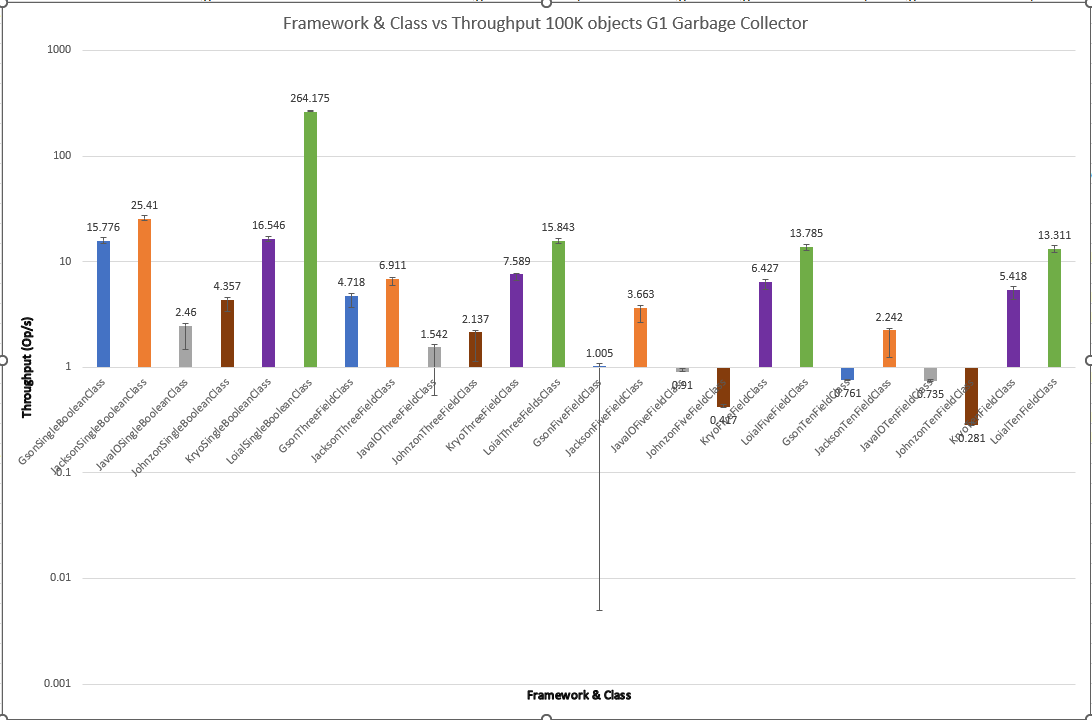
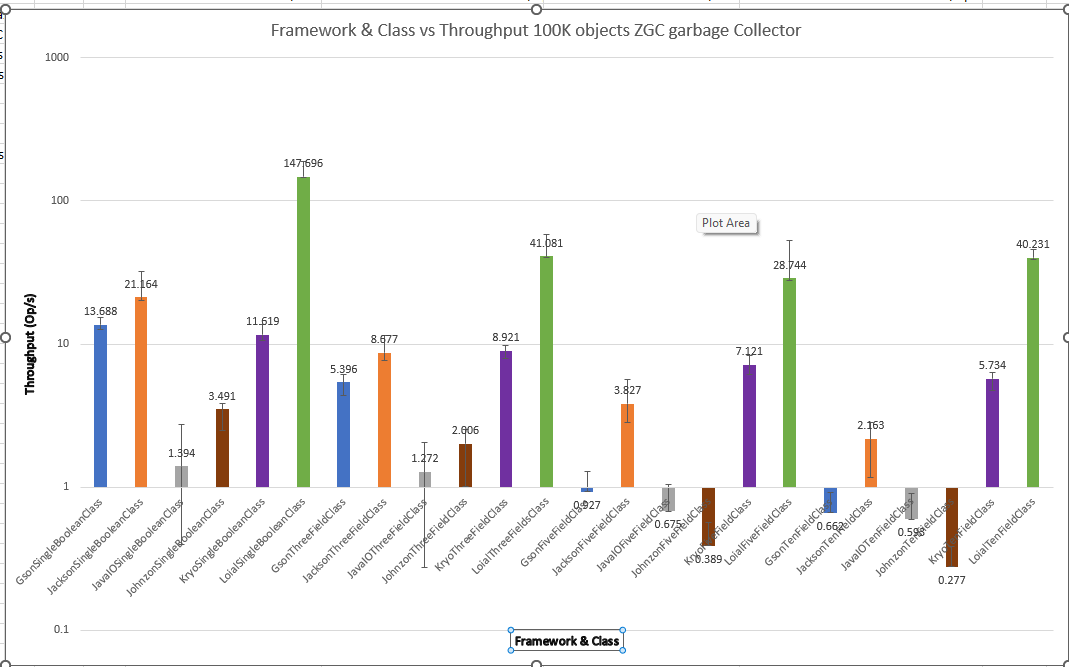
GC algorithm didn't play much of a role in the throughput performance of existing serialization libraries. Surprisingly, it seems to have more of an effect when Loial is included. Perhaps modern garbage collectors become more useful when software achieves higher throughput.
G1
ZGC
Shenandoah
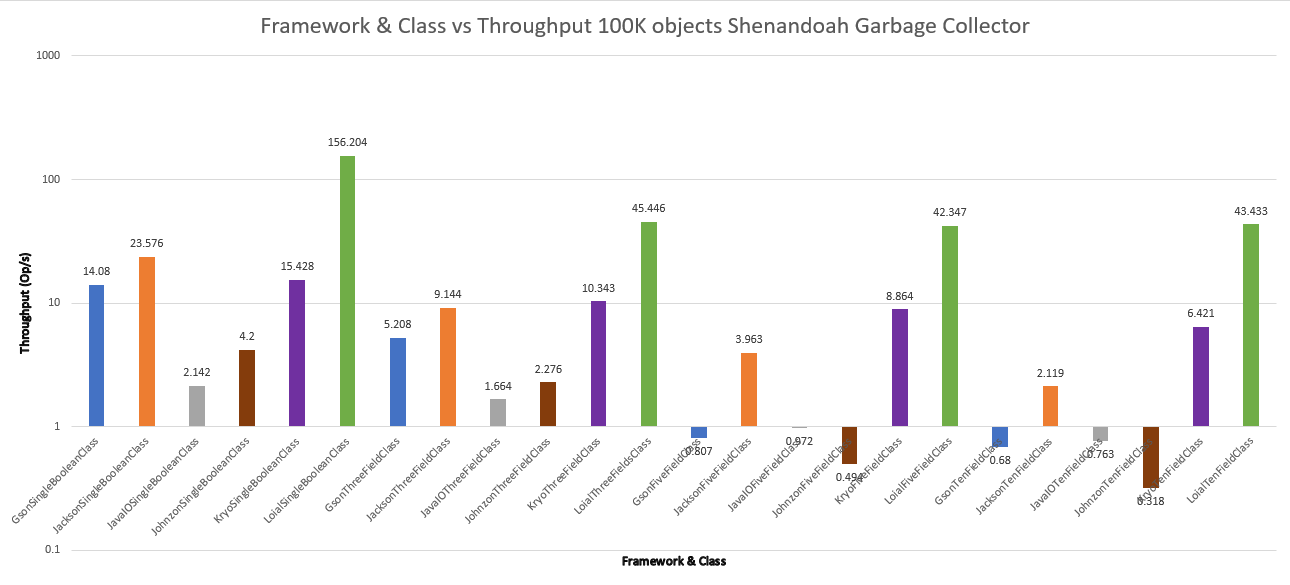
Interestingly, while the other frameworks were about the same between GC algorithms, Loial was much more effective with ZGC and Shenandoah for ThreeFieldClass, FiveFieldClass, and TenFieldClass. 20x throughput over Jackson and 7x over Kyro in the most extreme case is quite different from 6x and 2x for G1.
Discussion
Loial consistently outperforms all other offerings by a large magnitude, while Streams’ repeated problems pushed me to either fix or deprecate. I don’t think it’s worth the effort to “fix” an approach that seems fundamentally flawed, so I decided to deprecate it. I’ll omit Streams from further analyses–its value as a learning exercise and model for unification API have earned it a long rest. Loial’s differences become even more apparent when we examine the leanness and quality of the libraries.
Quality
SonarQube
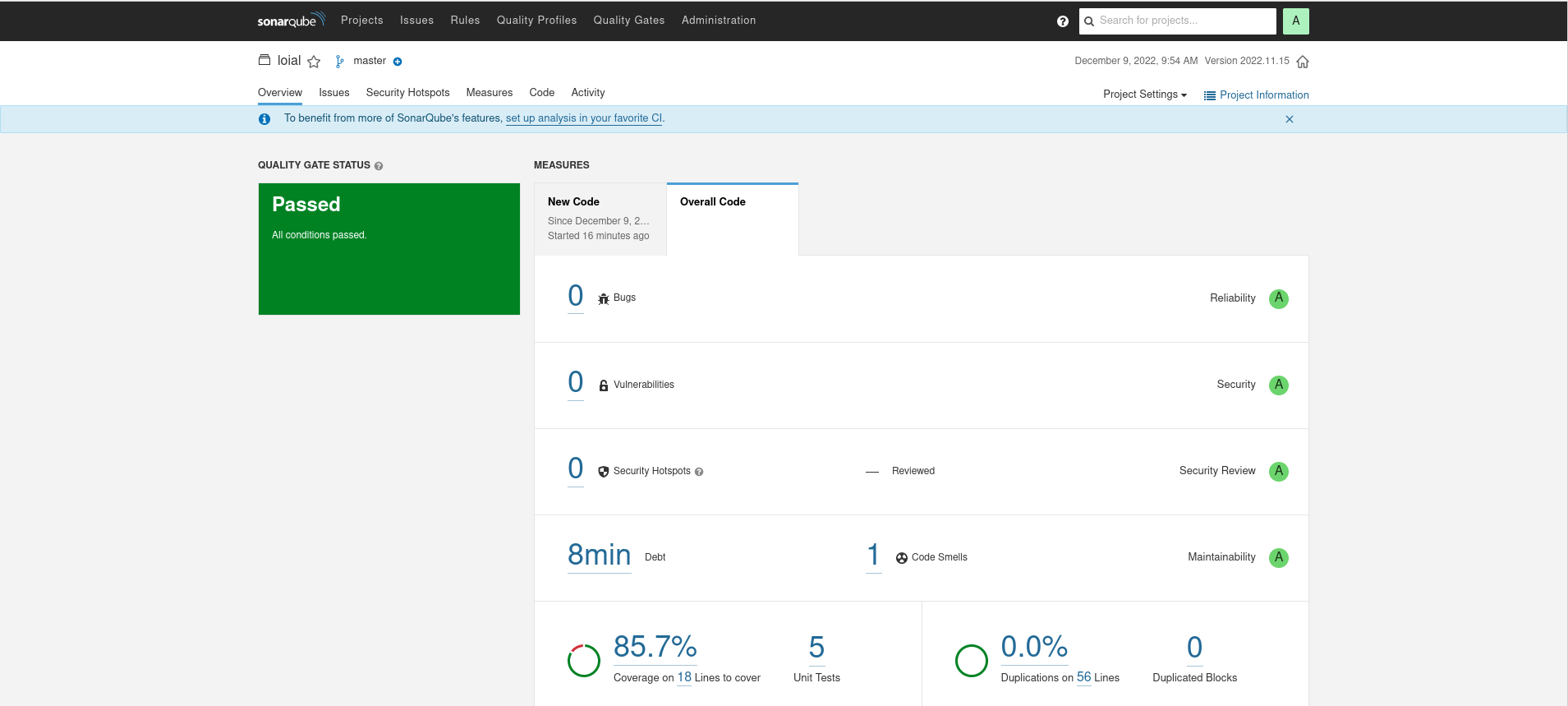
Loial
As a reminder, here were the SonarQube results for Gson, Jackson, Johnzon, and Kryo. Note that Java IO was too difficult to get into Sonar, Jackson Databind had errors in its JavaDoc that made it impossible to import, and Kryo’s unusual project structure made it difficult to get coverage information.
Gson
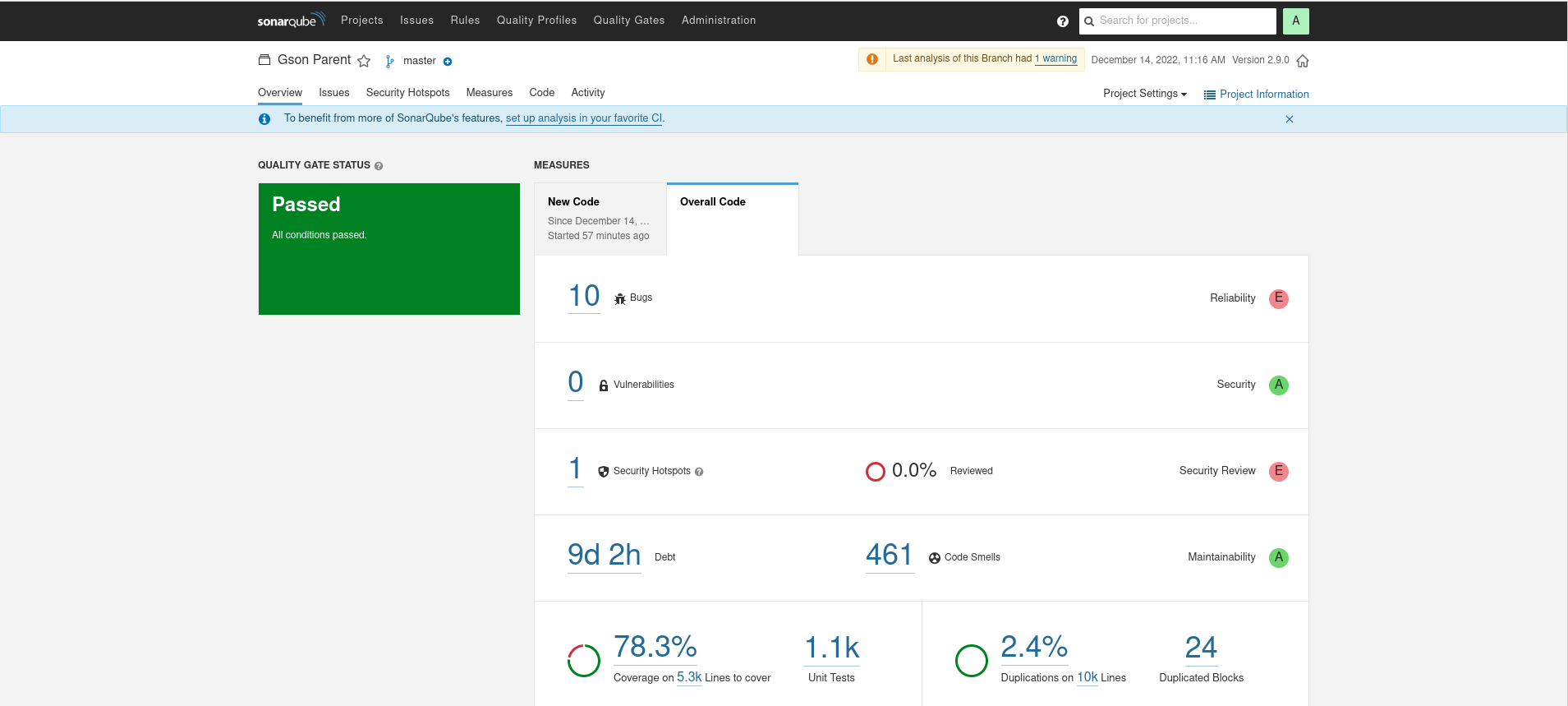
Jackson
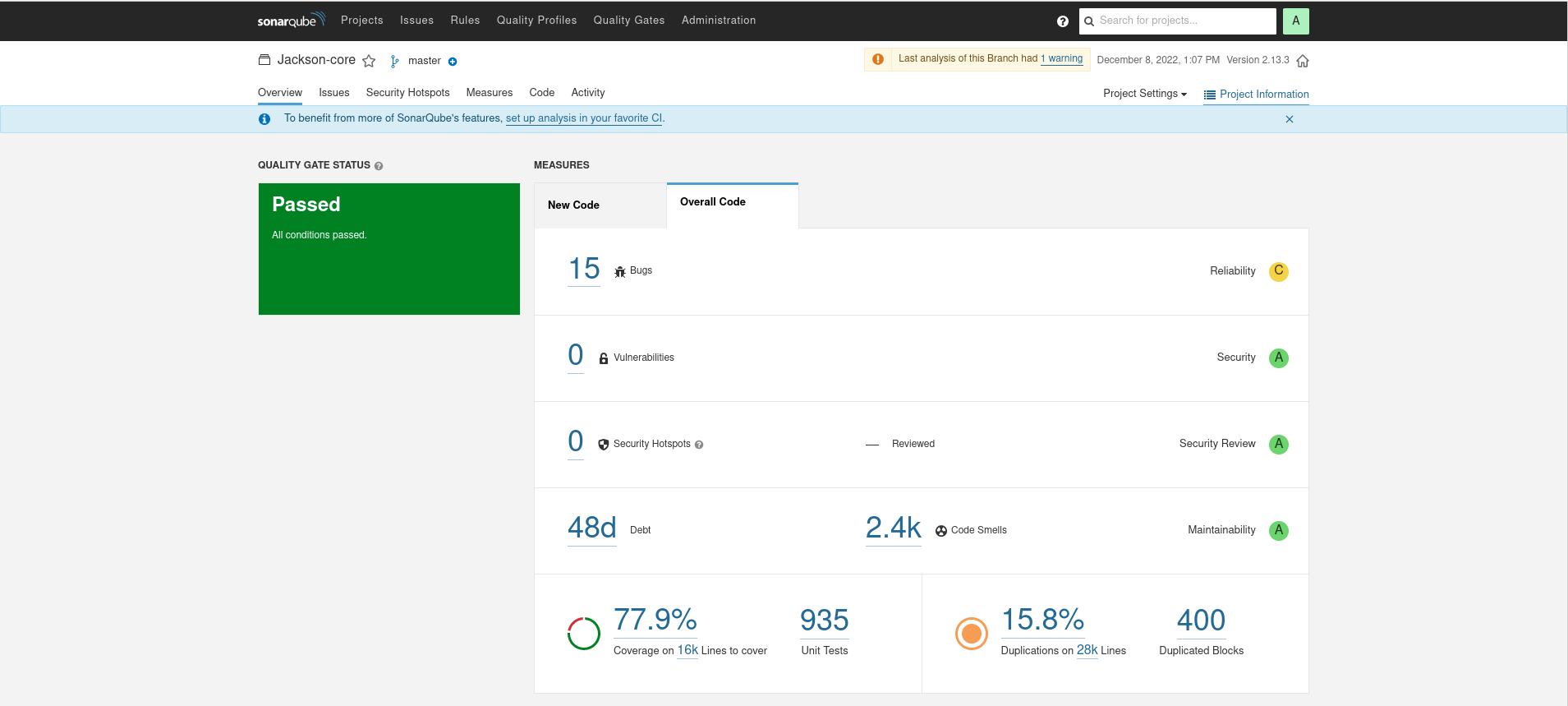
Johnzon
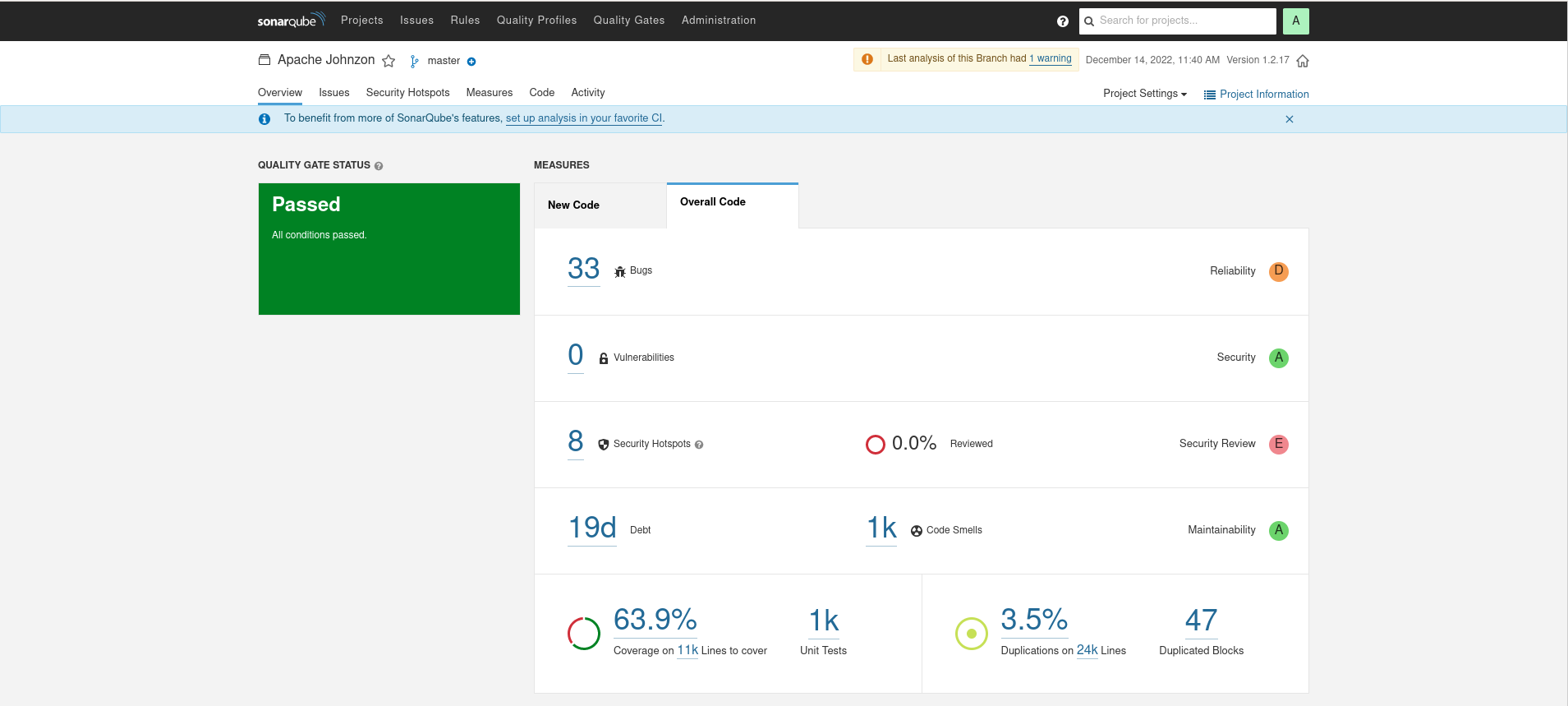
Kryo
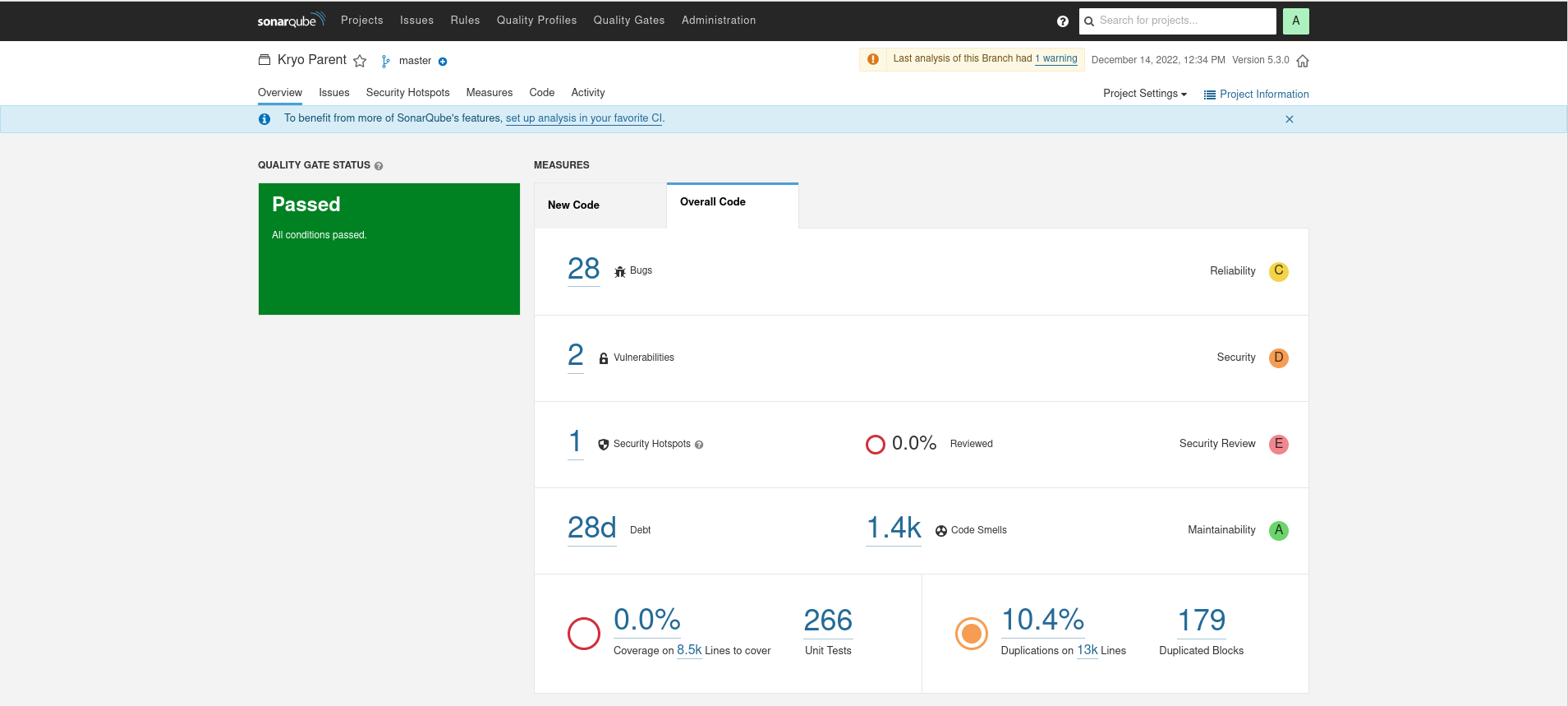
Loial has higher code coverage, less lines, less perceived bugs, and less computed technical debt than any other offering.
Leanness
SCC
Loial
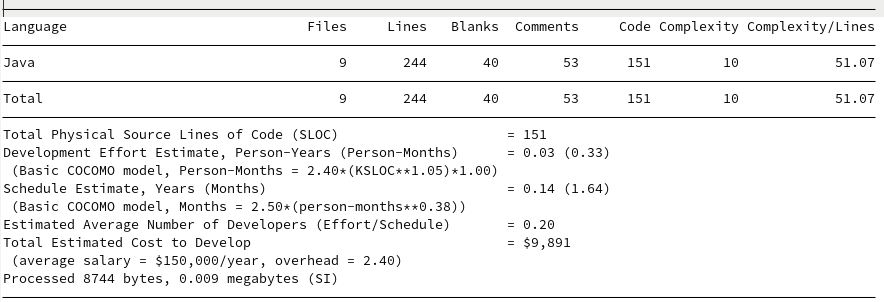
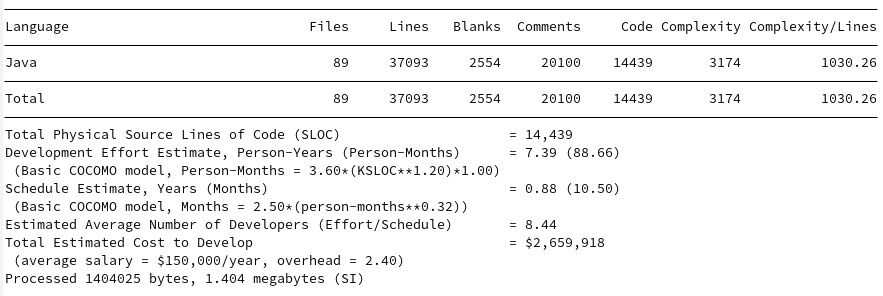
The comparisons to the existing options make Loial look like child’s play. For a review, here are the SCC outputs for Java IO, Gson, Jackson, Johnzon, and Kryo.
Java IO
Gson
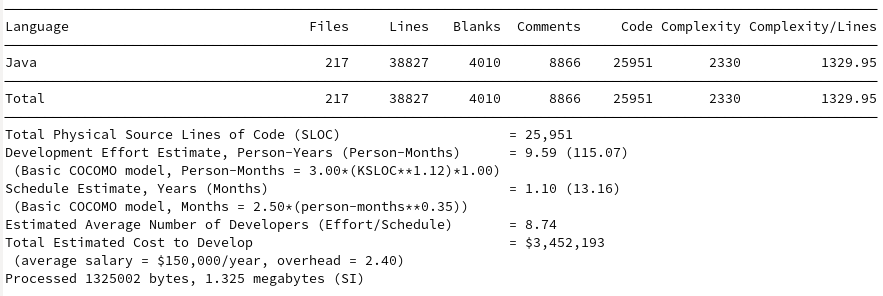
Jackson
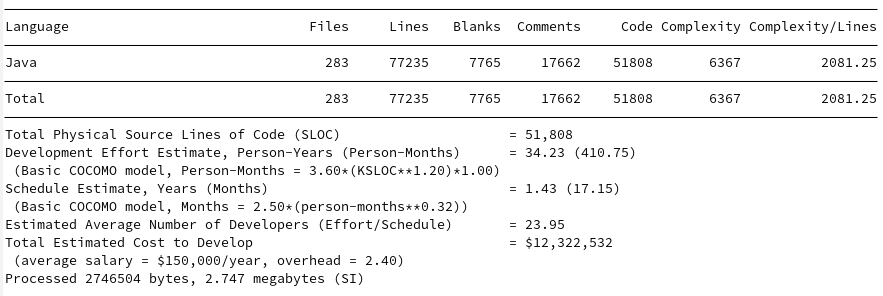
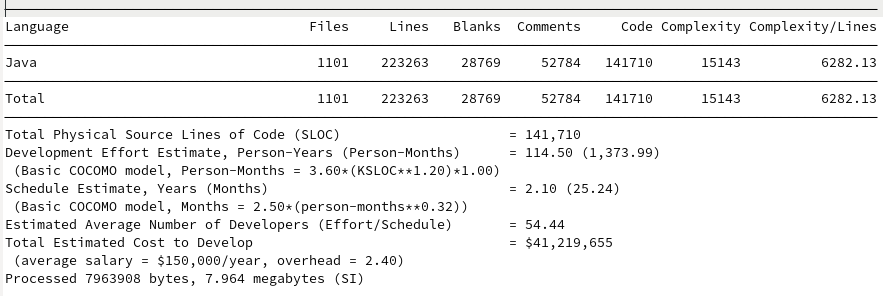
Johnzon
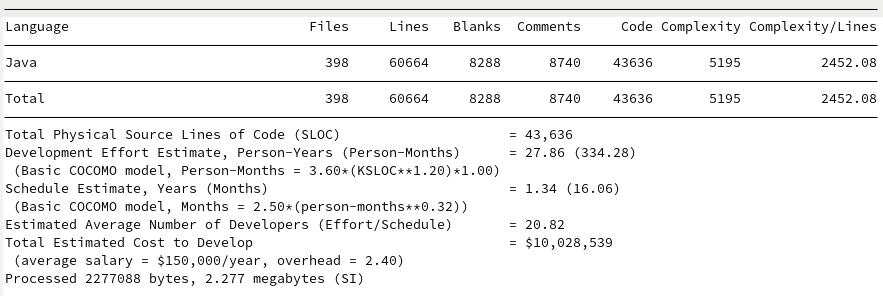
Kryo
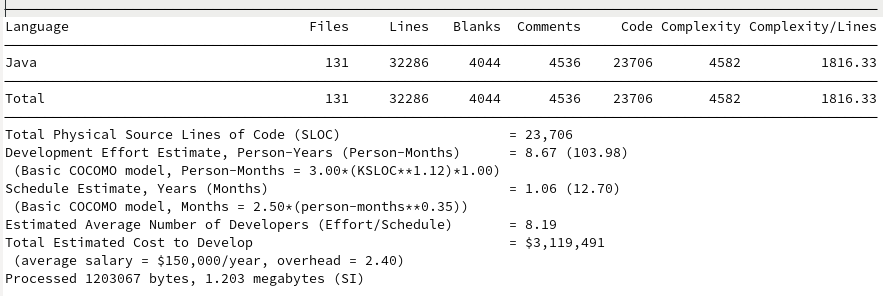
Loial clearly contains fewer files, lines, code, complexity, and budget than any of the top products on the market, at least by metrics easily derivable by SCC.
Conclusion
Throughout my career, I’ve often heard developers say that they write difficult to understand and reason about code “in the name of performance.” I’ve often suspected these claims to be specious. I now have strong empirical evidence to support my suspicions.
The same phenomenon that Paul McCready showed with human flight applies in software: it is possible to do more, with less. The same beauty Buckminster Fuller argued for can be chased and accomplished in software. The idea that performant code has to be ugly is an excuse and a canard.
I’ve continually seen complexity propagate. As software eats the world, many just accept that as hardware capacity grows, software should just become more arcane and complex. As the adage goes, "Grove giveth and Gates taketh away." Wirth’s Law has been restated over and over again for over 30 years, yet software continues to get more complex. I hope that this work can serve as software example of the genius and courage spoken of by E.F. Schumacher.
I’m hopeful that the general availability of a quality serialization benchmark will enable serialization framework authors to compare their performance and optimize it. Perhaps the definition and example of a reference architecture for object serialization will inspire future programming language authors to implement it directly. Even existing languages can incorporate it and evolve their APIs–in much the same way Java built NIO after IO and a new Date API replaced the Calendar API, a new serialization API can supersede and deprecate the existing.
There is a wide space for future work. I’d love to see the performance benchmark expanded to include more libraries and truly become a comprehensive “insert your object model here, try it with the option space of libraries, choose the best” type of offering for engineers. I’d like it if some of the JMH benchmark code itself, which is a target for code generation and pretty barebones, could be generated. There is of course still more possibility with Loial, providing generated SerializationStrategy for common output formats like JSON and YAML would be useful for programs intent on tying themselves to such regardless of the performance implications. I’m also curious to explore some of the implementation ideas I thought about, such as parallelism and runtime encoding. Knowing that I can look at object serialization and pare it down to bare essentials, I am curious about reference architectures for other interesting problems. This same style of approach would be very helpful in deciding between the slew of Java HTTP and/or app servers available. Perhaps Inversion of Control Containers could also benefit from this type of approach. Efficient object serialization can serve as a building block towards other frameworks, like RPC service frameworks or the ever elusive Richardson Maturity Model Level 3 REST architecture. I’ve also never seen a simple and minimal microservice framework for CQRS with Event Sourcing.
There are many possible directions. I believe good engineering is beautiful. I believe beautiful engineering can inspire the kind of awe we typically reserve for a masterpiece painting or sublime passage of music. I commit to furthering the revolution–with genius and courage– against unnecessary complexity and the entropy it brings to systems. But what I know for sure is that whatever I make next, I commit to making it simple, high quality, and fast. I know I can.