
Get the code from Bitbucket. If you find this useful, donate to the cause.
Best Practice Performance Comparison for Java Serialization libraries
Applying JMX with a rigorous scientific methodology crafting extensible performance experiments
By Nico Vaidyanathan Hidalgo
What is this all about?
Software engineers seeking to choose or validate technology choices often seek out performance comparison of different serialization frameworks. Searching the internet reveals many articles on the topic. Unfortunately, many authors are inexperienced with best practice Java benchmarking. They sometimes write faulty benchmarks. They sometimes only benchmark a single library. They sometimes only provide results, without accompanying source code.
Lacking a suitable example of an extensible performance benchmarking micro harness where I could evaluate the performance of my serialization library against others, I wrote my own. This work describes, implements, and open sources a reusable and extensible benchmarking harness for Serialization library comparison.
Why is this necessary?
Serialization decisions can have a large impact on the cost in hardware and development time of software. Developing ad hoc benchmarks for serialization library performance comparison often takes its own development time and effort; it can easily be done incorrectly. A freely available and minimal benchmarking suite with proper experimental setup can significantly speed up this process. With such a benchmark, engineers can focus on more value-added work such as testing performance in custom contextual environments, comparing different versions of library performance to investigate regressions, or adding new libraries for a broader comparison.
When is this analysis taking place?
This work began in Q3 2022. The Java Micro Harness framework is the currently known best practice for measuring performance in Java. The Java version evaluated is OpenJDK 17 build 17.0.1+12. Gradle 7.6 is used for the benchmarking project. The documented JMH build plugin for Gradle is 0.6.8, using JMH 1.35. The benchmark compares Kryo (5.3.0), Jackson (2.13.3), Gson (2.9.0), and Johnzon (1.2.17). I run the benchmark on an Arch Linux VM (2022.04.05-x86_64) with 32 GB and 4 virtual CPUs allocation.
Who is the target audience?
Software engineers experimenting with different serialization libraries to choose one for their projects. Students, researchers, and other technically minded professionals may find it useful, as well. The benchmark is available on BitBucket for personal use under a GPLv3 license.
Where can someone interested learn more?
The reader should have a strong working knowledge of Java. In order to keep this report focused, I will not explain JMH in depth. I refer the interested reader to its documentation and code examples. I recommend prior experience with at least one serialization library and the concepts of serialization.
How should we construct a performance benchmark?
Generally software engineers define code performance in terms of CPU and memory. JMH provides basic instrumentation for stack trace analysis and garbage collection; I enabled both in the benchmark. Object serialization performance generally depends on the structure of an object–the number of fields and their data types– and the number of objects being serialized.
Number of objects
In my own experience building frameworks for large-scale distributed systems such as the Amazon retail website and Amazon Web Services, I’ve seen how serialization approaches that are deemed “good enough” for rates of 10-100 objects per second can become an issue at 10K+ objects per second. Therefore, it seemed worthy to investigate the number of instances to serialize. 1 can serve as a good “baseline”, but it’s worthy to check the assumption that raising the number of instances by an order of magnitude (10, 100, 1000, …) changes the throughput by a similar order of magnitude.
Number of fields
The amount of data in an object clearly correlates with the amount of time and memory needed to serialize it. The amount of data within an object relates to both the number of fields and their data types. Java’s primitive data types offer specific size guarantees– such as an integer/float is 4 bytes and a long/double is 8 bytes.
As the minimum size of data in registers understood by the JVM is 1 byte, a minimum viable object of a class with 1 boolean/byte field can serve as a baseline for the smallest possible object to serialize. Intuitively, we might expect linear relationships. For instance, we might expect that an object with a single boolean field that is serialized and deserialized would take 1/2 the time of an object with two boolean fields, which would take ⅔ the time of an object with 3 booleans. This intuitive expectation is worth testing.
Various fields with different types
Most real world objects, however, are not homogenous. Comparing the serialization performance of an object with 3 integers versus an object with 4 integers may provide some insights into whether the serialization library performs any kind of internal optimizations, but is unlikely to reflect common usage conditions. Therefore, I made some objects with a heterogeneous number of fields and data types which would more likely model commonly serialized objects.
Mutability
Software Engineers began to discover the value of immutability in the 2000s as interest in distributed systems development grew. The challenges of managing distributed state were greatly simplified if state could be minimized. Such thinking led to an increased popularity and emphasis in immutability.
Immutable objects have interesting properties. Immutable objects without state-changing behaviors function essentially as values. Rich Hickey extensively enumerates the benefits of values in “The Value of Values”, with some of the more important implications being that they are easy to construct and easy to communicate.
In practical terms for a serialization framework, immutable objects eliminate the need for complex deep-copy semantics, can enable a non-reflection based declarative serialization strategy, and enable compact representations similar to enumerations. In principle, a serialization framework with memory of seen values can apply entropy coding techniques to compress objects and reduce payload sizes.
Garbage Collection
One often under-considered element of software’s performance is the effect garbage collection can have on the overall profile. This effect becomes more readily apparent in languages like Java for web services performing tens of thousands of transactions per second. In such scenarios, a “stop-the-world” garbage collection can feel relatively devastating, massively inflating p90 and p99 latency metrics.
Garbage collection varies directly according to how code is written–how many intermediate objects are created and fall out of scope directly impacts the book-keeping done by garbage collectors, the frequency of their runs, and the overall effect on the system. In this way, the garbage generated by a particular serialization framework can be significant.
Another interesting consideration is that although the JVM has a configured default garbage collector, G1 since Java 8, other algorithms such as Shenandoah and ZGC have seen active development. Mature performance analysis should investigate different garbage collection algorithm options and their potential interaction effects with a serialization framework.
User Stories for a useful Java Serialization Library Comparison Project
- The project should be self-contained and runnable with minimal setup
- The project should use gold standard mechanisms for performance that can withstand the scrutiny of experts, such as JMH
- The project should enable investigators to tweak experimental setup/JMH parameters easily
- The project should enable investigators to simply modify the experiment itself– such as adding different model data classes or integrating a new serialization framework for analysis
Realizing the Vision
I store the project in Git source control, which makes cloning the project straightforward for anyone with internet access. I use Gradle along with the wrapper to implement “self-contained and runnable with minimal setup.” Simply the following suffices:
git clone https://bitbucket.org/visionary-software/serialization-performance.git && cd serialization-performance && ./gradlew assemble jmh
The project uses JMH with the Gradle plugin, which allows customization of JMH parameters via arguments in the benchmark’s build.gradle.
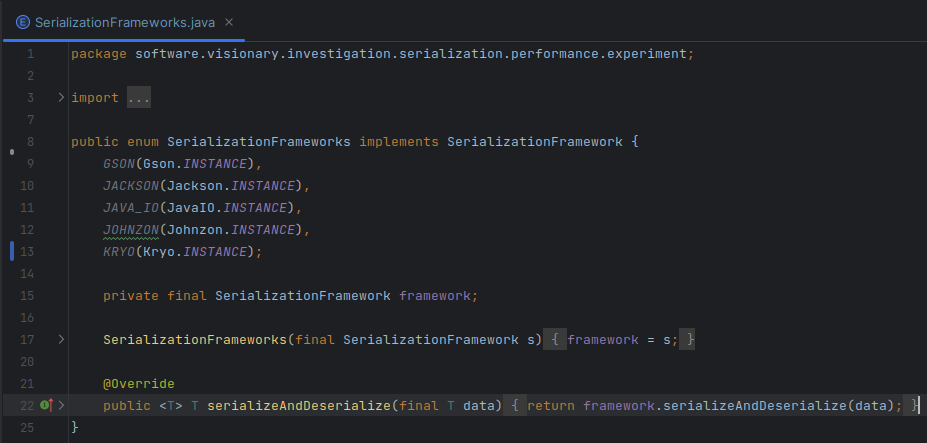
The project consists of a benchmark module.. This module contains both main and jmh source directories. The main source directory module houses the base interface that implementations should use to encapsulate a serialization framework.
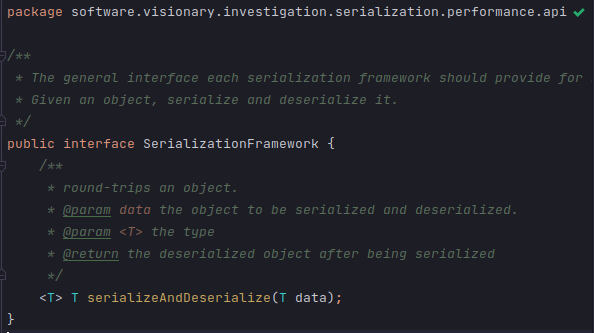
A couple of examples can illustrate the common pattern. The first example encapsulates Gson. The second encapsulates Jackson.
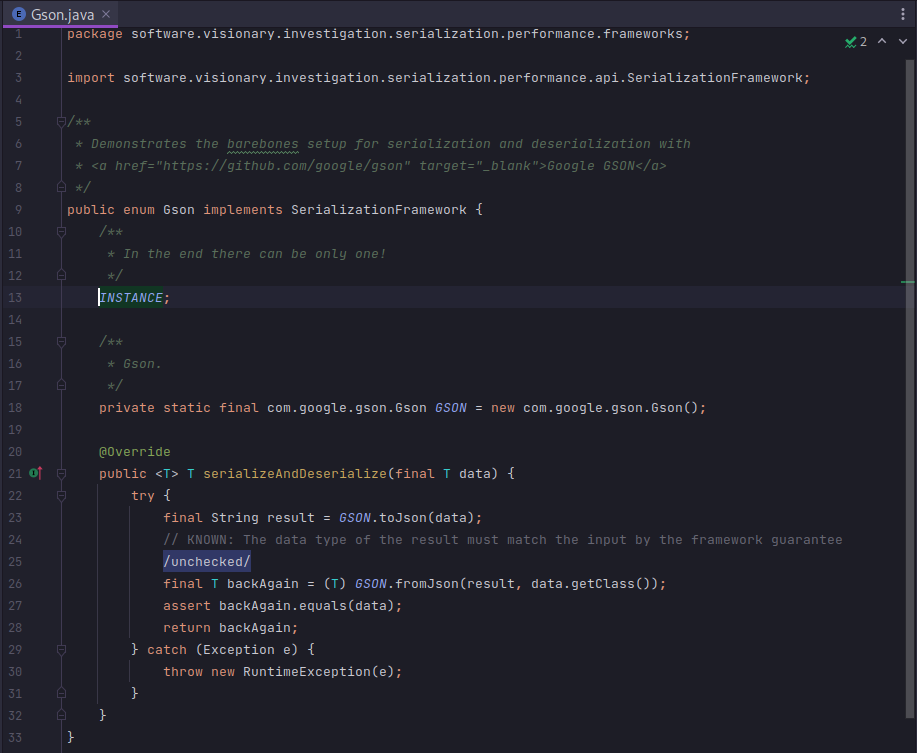
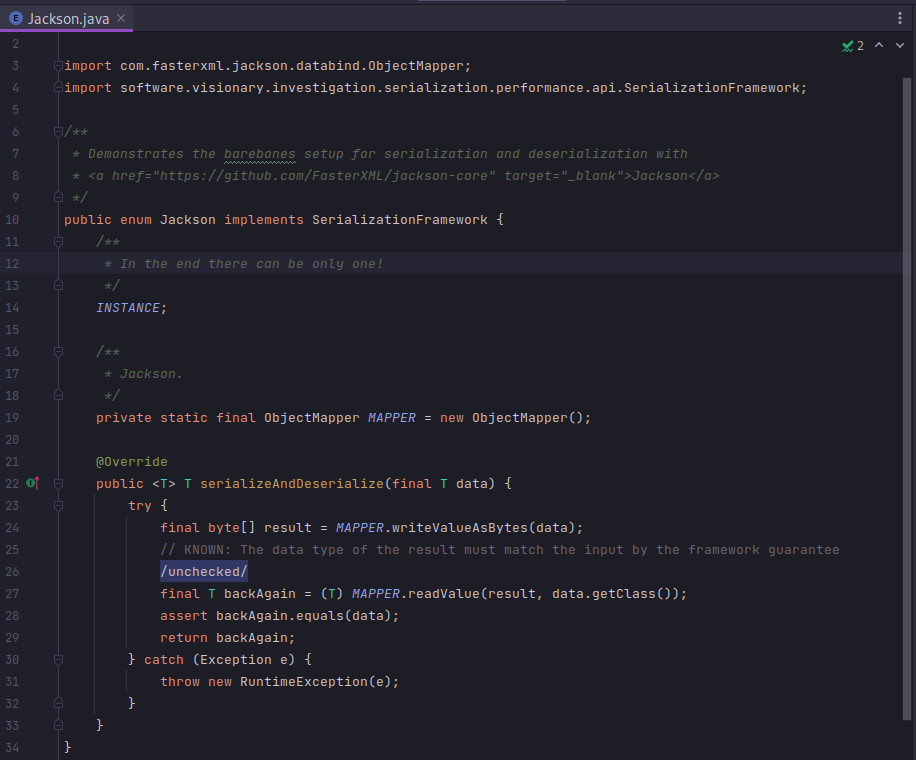
This style allows the model objects to be completely orthogonal. An interested investigator could copy-paste their own object model into the project and run the setup for precisely the types of objects they generate in their systems. This makes the gap between “synthetic benchmark” and “directly applicable experimental setup” quite small.
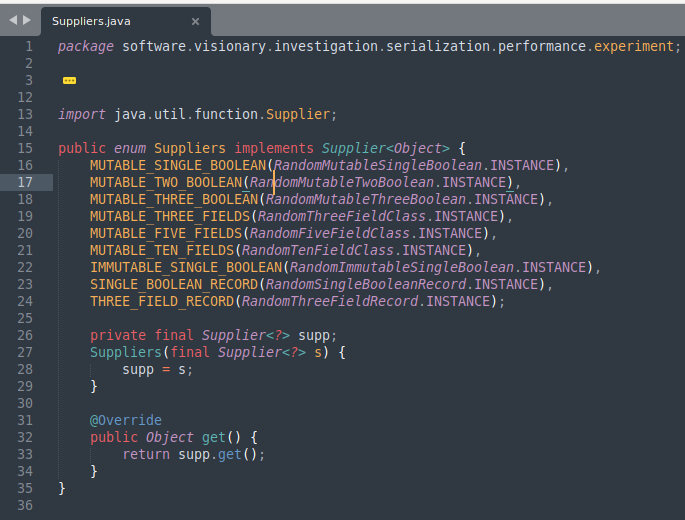
In order to explore the relationship between number of fields and serialization framework performance, I created a variety of model classes with 1,3,5, and 10 fields. A couple of examples are shown below.
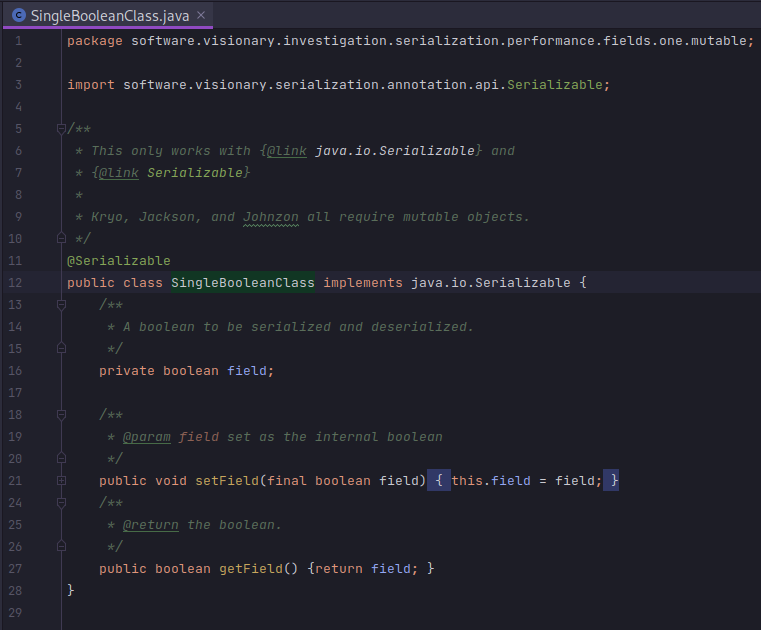
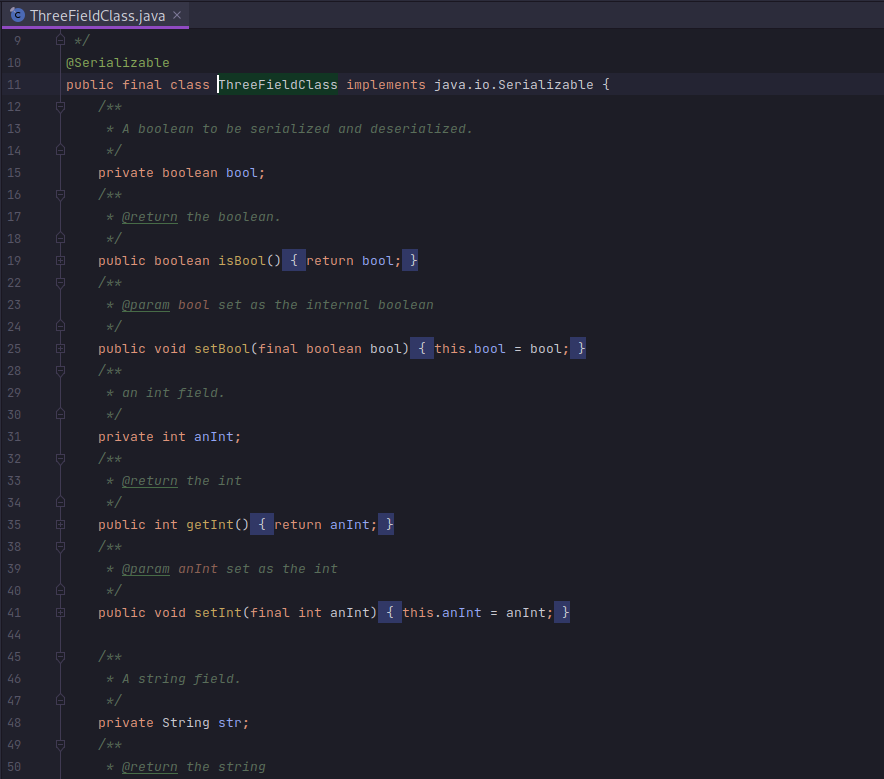
With these models in place, I want to construct instances with random values (in case any caching or cleverness is applied by the frameworks) and feed them into the benchmark. I used java.lang.Supplier as a FACTORY METHOD. A couple of examples will illustrate the point.
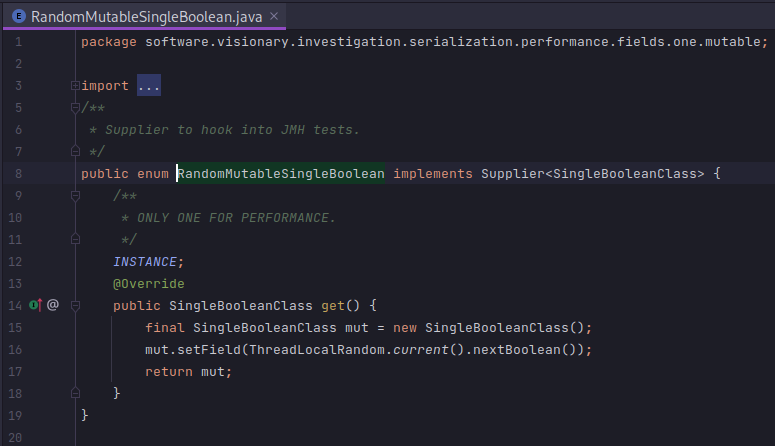
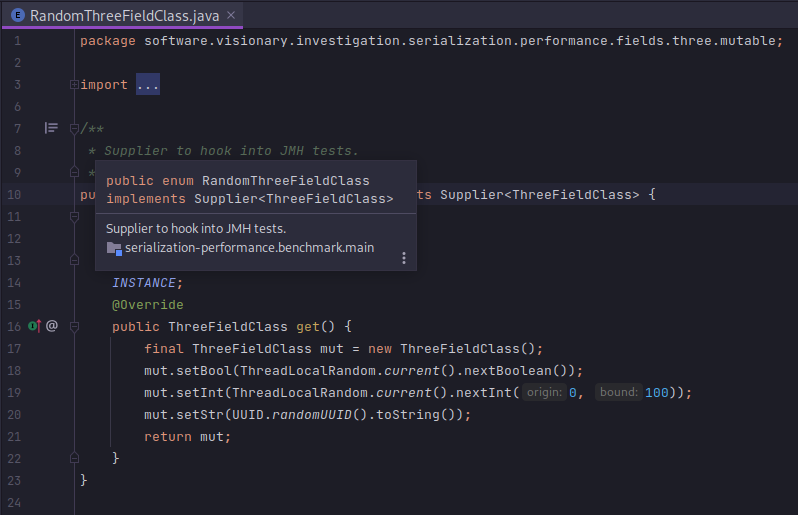
From there, it is simply a matter of wiring up the serialization framework with the suppliers. I use JMH @Param
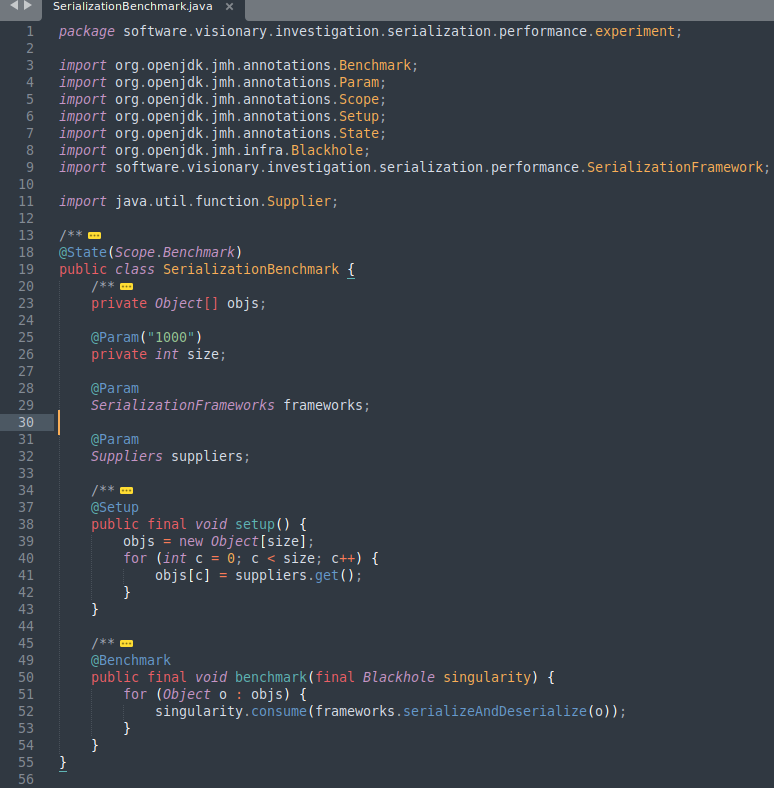
Excited to see where this is going? Check out the results!