
Mapping the Serialization Territory
Motivation isn't enough. You have to know what exists.
By Nico Vaidyanathan Hidalgo
Introduction
In part 1 of this series, I defined fast, lean, and high quality as the primarily desired traits for object serialization. But object serialization is not a new problem. It’s worthwhile to examine existing serialization libraries, exploring their approaches for speed, leanness, and quality. It’s also worthy to analyze their design from a broader perspective: how similar are they? Does changing the serialization technology a piece of software uses often necessitate a complete rewrite of many architectural components? Can they be unified behind a common serialization “bridge” API–like Simple Logging Facade (slf4j) in logging?
What is Object Serialization?
Objects organize data in memory according to their defined semantics within the programming language. Transferring that data to other environments–such as for persistence or transmission across a network– often requires conversion. Serialization is a general, well-understood term for this process. It is not the only term. Ruby calls it Marshalling, a common phrase in the 1980s for such operations also included in Robert Martin’s Clean Code--though used there for command line parameters. .NET also uses “serialization” and “marshalling”. Python calls it “pickling”. Yet common usage of “serialization” occurs in their documentation as well, and “serialization” is so common that it is even used in the documentation of “exotic languages” like Haskell and Julia.
Bytes? Can’t Objects be serialized to JSON/XML/CSV/YAML/...?
Many works also describe data formats such as the JSON, XML, and CSV as “serialization.” This arguably abuses terminology.
In the early days of computing, it was quite common for software companies to develop everything from scratch. This usually included both binary encoding for objects and their transmission protocols. As the desire for interoperability rose, software engineers started pushing to adopt more unified standards for object representation. This led to the rise of efforts like CORBA, RMI, and web services described in WSDL. As the World Wide Web exploded in popularity and network systems became the norm, using strings across the wire became another de facto standard. Hunt and Thomas' Pragmatic Programmer provided a watershed moment. They argued, quite convincingly, that human-readable string formats are superior for readability, debuggability, and extensibility. Nevertheless, it's worth considering the performance trade-off.
Consider the case of a birthdate. For simplicity, assume ISO8601. Figure 1 shows a basic Java class representing this concept–let’s ignore the lack of error checking for now, it’s not relevant for this example.
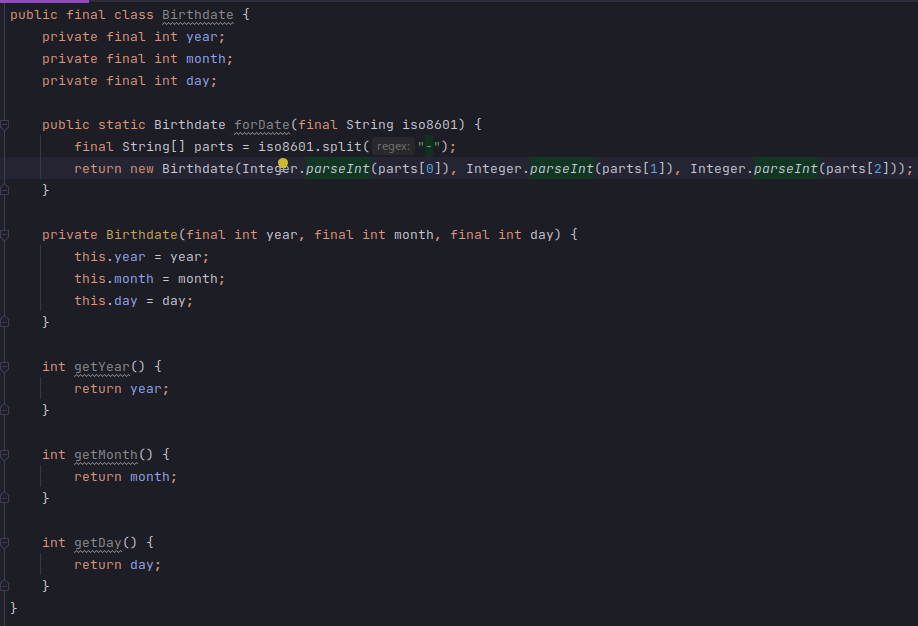
A birthdate in ISO8601 is represented as YYYY-MM-DD. Assuming a UTF-8 encoding, each glyph requires 2 bytes. Hence a string of 20 bytes in extended representation.
Integers are 4 bytes, so a birthdate transmitted as 3 integers requires 12 bytes. Clearly a savings. Can the size be reduced further?
Further optimization realizes that valid months (1-12) can be represented in only 4 unsigned bits, and valid dates (1-31) can be represented in 5 unsigned bits. Years are domain dependent. An 8 byte Java Long can go back to the Big Bang and forward to the projected Heat Death of the universe. Most domains dealing with birthdates, however, don’t need such length. If a particular domain requires birth dates within a bounded range, such as 1920+128 years, it is possible to use 7 bits to represent the year. In such a domain, one can represent a birthdate in 2 bytes.
Software engineers have long known the difference in efficiency between text and binary formats. Yet often such concerns are described abstractly in the literature, which can downplay the extent of the impact. Service Oriented Architectures with web services at a scale of thousands or more TPS often have significantly different performance profiles and resource needs when payloads are orders of magnitudes smaller. Such differences can really add up.
Investigating existing serialization libraries
As object serialization is a standard problem, many solutions have been developed for solving it. From a purely theoretical point of view, analyzing and comparing the entire population of solutions would be ideal. From a practical point of view, the amount of work necessary to discover, collate, and analyze dozens/hundreds/thousands of solutions is prohibitive. Consequently, I sample available solutions.
Sampling itself is a bit more art than science, with certain risks and biases attached. One risks omitting important libraries that many software engineers would likely want to try. Nevertheless, using intuition from field experience with thousands of Java projects, as well as my perceptions of library popularity by others, I’ve chosen a handful of libraries to review. I outline some rationale for excluding others.
Ignoring certain options
ProtocolBuffers/FlatBuffers/Thrift/Avro/MessagePack
Projects such as Google’s ProtocolBuffers and FlatBuffers, Apache’s Avro and Thrift, and MessagePack offer options for language-independent data serialization. Arguably they represent an advanced approach to serialization.
These projects apply a Schema First model. In Schema First, an object’s structure and data format are pushed outside of the code of a particular application. This allows for cross-platform sharing–such as serializing an object in Java and deserializing it in Ruby– and swapping a format such as XML to JSON to save bytes.
The downside of these options is that they generally force the use of separate extra-linguistic definitions of structures written according to their specification. A project that uses one of these options includes the library dependency and modifies its build process to generate code from these definitions. This extra setup is unnecessary in projects where Java is known to be used on both sides of serialization/deserialization.
They add some conceptual complexity–projects using them must learn an additional format and syntax outside of the code itself. Applications content to ignore schema and wire format as implementation details may find such complexity not strictly necessary. Tools such as the Java Serialization framework or Jackson function well for such applications.
They also invert the thinking of the application development process. Rather than writing Java classes and defining their serialization format later–so-called Code First– users should define the type in external files and rely on generated code–so-called Schema First. An ideal solution would enable Code First style development and be able to generate the platform-independent schema from the Code.
Java is particularly well-suited for this. Annotation Processing allows a build-system independent approach to code generation as the Java compiler itself generates the code—rather than an external tool or a plugin integration into a build system--and there are many in Java like Ant/Maven/Gradle/SBT/Bazel/etc. Once the rules for mapping a Java object to some platform independent schema are well known, generating the schema from an object can simply be integrated into an annotation processor.
Without commenting on the viability or effectiveness of such tools, I will omit them from analysis. I do not want to take on the additional overhead of writing extra files for objects that I plan to be canonically defined in Java classes, simultaneously learning different specifications such as Avro schemas or ProtocolBuffer messages and incurring the cognitive load of mapping between them. I believe the right Serialization API in Java enables usage of such tools seamlessly without disrupting a Code First iterative development process.
Random JSON/XML/YAML bespoke library
The wide selection of available serialization libraries complicates broad sampling. Results discovered can be greatly influenced by search methodology, including what the precise search query is, when the query is made, which search engines are used, geographical location of the query, and more. Some libraries discovered but not explored in-depth during my inspection include:
| Library | Reason for exclusion |
|---|---|
| XML Simple | I don't want to have to change the models to use library specific annotations |
| LoganSquare | I don't want to have to change the models to use library specific annotations |
| RuedigerMoeller fast-serialization | both 2.56 and 3.0.1 require breaking module system encapsulation by adding overly broad opens |
| Azrael | Not on Maven Central, only distribution seems to be from source control |
| nanoJSON | Low level JSON parser, doesn’t directly support object serialization |
| mJSON | Low level JSON parser, doesn’t directly support object serialization |
Why not include these libraries? Many I had never heard of before some searches on Google in late 2022. Many have specific implementation issues that I believe hinder an overall design, like a proliferation of annotations. I have yet not found enough evidence that these are advanced enough in adoption, performance, or architectural novelty, to warrant further investment. Based on community feedback and reception, I may include them at a later date
Selecting serialization libraries for analysis
| Library | Reason for inclusion |
|---|---|
| Java IO | Any evaluation of serialization in Java would be remiss to ignore the option built-in to the standard library. Clearly developers have repeatedly evaluated it and found inadequacies, hence the explosion of different library options in the Java space. It’s worth exploring why. |
| Gson | Gson is a dated library at time of writing. Gson started development in 2008 and is listed in maintenance mode on its homepage. Nevertheless, it is an extremely easy library to use and broadly adopted. I witnessed its use in 1000s of projects at Amazon, I’m confident it’s used in millions more around the world. |
| Jackson | FasterXML’s Jackson is often regarded as the gold standard of Java serialization libraries. It offers a combination of speed and flexibility. It is commonly included in serialization option comparisons and also used in millions of projects around the world. Jackson is quite large and feature-rich, including annotation-based data binding, custom serialization strategies, and different wire formats such as Smile and CBOR. |
| Johnzon | Apache Johnzon marks a relatively recent entry into the Java serialization space. Its development started in 2014; it offers a full implementation of JSON-P/JSON-B (JSR-353 and JSR-367). An official Apache Software Foundation project implementing Java Enterprise Edition specifications, it may be seen as a robust and interoperable offering aimed for broad usage in enterprise environments. I don’t have much insight into how widely adopted it has been, but I expect it to be an attractive option for future development based on the permissive license of the Apache project and ubiquity and evolution of the Java Enterprise Edition specification. |
| Kryo | Esoteric Software’s Kryo has repeatedly surfaced in my searches on performant serialization libraries throughout my career. I first found it mentioned when I was investigating the design of a serialization replacement for the Coral framework at Amazon in the mid 2010s, ranking highly in performance investigations of the time. Kryo supports customizable serialization and is easy to use, clearly making it a prime candidate for comparison. |
Conclusion
I’ve explored object serialization conceptually, from the ground up. From this understanding, I engaged in a survey of available solutions–choosing some of the most popular and omitting options with intensive setup. I analyzed the options I chose– Java IO Serialization, Gson, Jackson, Johnzon, and Kryo– via performance testing, static code analysis, and directed software archaeological digging through their architecture to generate class diagrams. Consequently, I’ve discovered a common architectural pattern to serialization that I can define with an API and implement as an alternative offering. The following pieces in the series will explore the definition of that API, implement it, and compare it with existing options.