
Architectural comparison of Java Serialization Frameworks
Exploring code through IDEs and PlantUML
By Nico Vaidyanathan Hidalgo
During part 1 of this series, I defined fast, lean, and high quality as the primarily desired traits for object serialization. This article dives into architecture. But what do we mean by architecture?
"Software Architect" is a fancy sounding job title that almost anyone who develops software for more than a handful of years feels entitled to use. After all, in software one basically designs the blueprints of the system and constructs it simultaneously--modern Agile software development does not practice the strong role segregation of "architects" and "programmers" that was common in the early days of software engineering. Doesn't one become an architect just by building systems?
In fact, the pendulum has gone so far away from the RUP and MDD that some even eschew the use of UML. Many respected professionals espouse ideas akin to "all diagrams should be on napkins" and "most upfront design is a waste of time." Someone might call themselves a "software architect" just by writing text documents and making "block diagrams" in PowerPoint.
This is an overall net loss for the software industry. While critiques of Analysis Paralysis and Viewgraph Engineering are poignant and important, the development of standard tools and templates for communicating software information "at a glance" was an important development. It is routinely under-utilized in many software development companies.
Cognitive Load Theory has conclusively shown that applying sequencing and chunking to manage Germane Cognitive Load is crucial to improving learning efficiency. That's similar to what good software architectural tools do. Rather than looking through dozens of files and thousands of lines of code, a good application of Krutchen's 4+1 View Model of Software Architecture can generate artifacts that greatly simplify onboarding for new engineers and can clarify and streamline communication between stakeholders. After all, as the saying goes, "a picture is worth 1000 words."
Coders love to code. They generally hate documenting the code. For good reason: one good fix is often worth 10 or more pages describing workarounds. But the act of consciously exploring existing code to attempt to generate class, activity, sequence, package, and component diagrams can actually serve as a far more effective investigation and learning experience than the more common "check out the code and read through it." It's like the difference between active reading and note taking versus passive scanning. Oftentimes warts of complexity in process that get lost in the detail of code can be surfaced just trying to diagram an arcane process.
With that in mind, I'm trying to revive the use of UML for capturing and communicating high level information about software structure and function in my own personal practice. Touring existing object serialization libraries and diagramming their inner workings provides me constructive work to truly discern commonalities despite superficial differences. It also creates the temptation to write programs to analyze the code of other programs and generate UML diagrams.
Comparing the architectures of libraries can be tricky. If libraries are feature-rich or include various customization options for edge cases, their apparent architecture can vary from how they’re commonly deployed. I’ve found the best way to begin exploring their architecture is to use them in an application and create a class diagram following the barebones usage model. From there, various different components can be explored to provide a fuller picture and determine exigency versus customizability. I use PlantUML to draw my class diagrams and present my results.
Java IO
The Java Object Serialization Specification completely defines platform included object serialization. Most developers, however, do not read the spec. Familiarity with Serialization usually starts with reading the JavaDoc of java.io.Serializable, java.io.ObjectInputStream, and java.io.ObjectOutputStream. An example of this can be seen from the benchmark project.
The mechanism principally appears simple enough to use, though many experience problems after repeated use. The framework offers various hooks to attempt to address these issues, such as writeObjectOverride()/readObjectOverride() for subclasses of ObjectOutputStream/ObjectInputStream to use –which leads to the Code Smell of extending concrete classes– and writeObjectReplace()/resolveObject() for handling potential security issues. A class diagram of Java serialization follows.
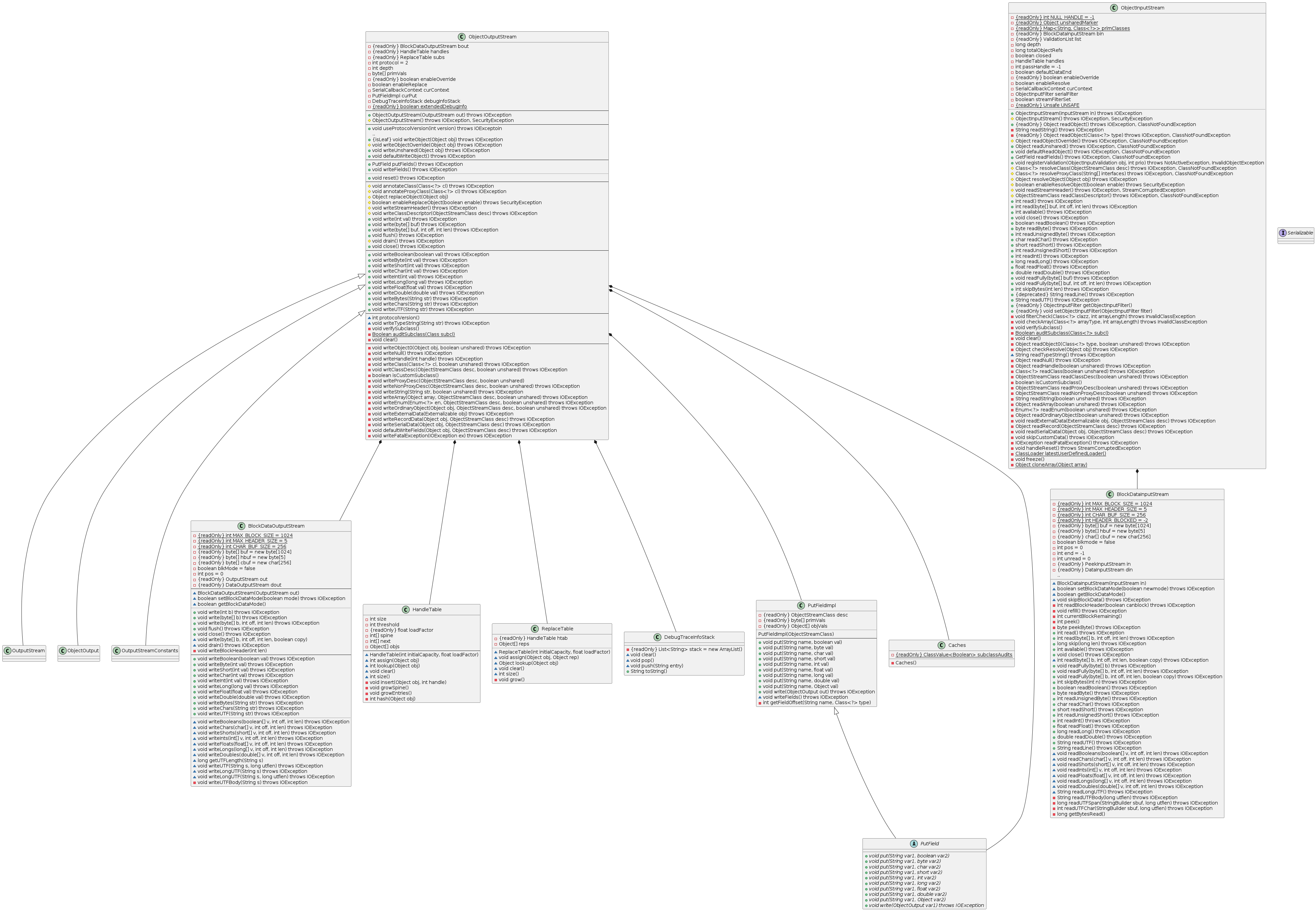
Observations of developer pain led Joshua Bloch to dedicate an entire chapter in Effective Java on Serialization, with 5 of the 78 total items– 74 to 78 in the 2nd edition– devoted to it. The items describe in detail how the design choices of the serialization libraries have serious security flaws and implications on correctness that aren’t readily apparent which necessitate careful design. Ultimately Bloch recommends using the Serialization Proxy Pattern, a Java specialization of what Martin Fowler describes as Data Transfer Object in Patterns of Enterprise Application Architecture.
“What we hate about Serialization and what we might do about it” by Brian Goetz and Stuart Marks reflects on all of the problems accumulated in experience with Serialization. Both seriously joke that serialization over the years has often been called “the most hated part of Java.” The pervasiveness of Serialization in Java, while perhaps instrumental to its successful adoption in infancy, created a slew of problems for evolving the language. While Goetz enumerates many of the retrospectively visible warts of “magic” and “extralingual mechanisms” that create security and invariant verification nightmares, a few further design critiques are worth mentioning.
Representing java.io.Serializable as a MARKER INTERFACE-- then using Reflection with private readObject()/readObjectNoData/readResolve()/writeReplace(), along with special private fields serialVersionId and serialPersistentFields– signals some design incoherence. As Joshua Bloch notes in Effective Java Item 37: Use Marker Interfaces to Define Types, the interface type is not even used within the body of the ObjectOutputStream.writeObject(), and “it didn’t have to be that way.”
Apparently the desire was to avoid introducing an inheritance hierarchy with TEMPLATE METHOD in order to meet the defined spec goal of “Have a simple yet extensible mechanism.” Forcing a serializable object to extend an abstract Serializable class with default hooks would preclude the object’s involvement in other inheritance hierarchies, because Java does not allow for multiple inheritance.
Yet, as Rich Hickey explained in “Simple Made Easy”, there is a wide and important difference between “easy” and “simple.” Promising the programmer ease–”just add implements Serializable”-- was “easy” marketed as “simple.” It is not actually “simple” to hide considerable complexity through reflective private method name string matching.
Likely there was a perception at some point that such methods should be less “magical”, as Java 1.2Beta1 had interfaces named Replaceable and Resolvable. These were purposefully removed by Java 1.2Beta4. As Java did not have interfaces with default methods in Java 1.2, forcing client classes to implement Serializable/Replaceable/Resolvable as interfaces with contractual methods probably would’ve added a lot of skeletal boilerplate code. The serialization library designers probably considered Reflection with a MARKER INTERFACE as a “hacked together TEMPLATE METHOD workaround”, allowing for customization if necessary while “doing the right thing 99% of the time” when not.
Yet adding default method implementations of readObject()/readObjectNoData/readResolve()/writeReplace(), along with special private fields serialVersionId and serialPersistentFields, to java.io.Serializable would not fix the problems with Java serialization. In fact, their very existence and necessity in the first place signals an accreting set of patches as implementers discovered the security and invariant problems. Some of the issues with Serialization are conceptual, deriving from the specification itself.
For one, many of the security and invariant violation problems of Serialization stem from what Goetz noted as “overreach.” The framework optimistically complected object graph walking, field scraping, encoding/decoding, and object reconstruction with the desire to serialize and deserialize arbitrary object graphs. An arbitrary object graph perspective invites a model where a byte stream can contain heterogeneous data–including primitives and data from other objects– along with a particular object’s data, and back references to other objects. This opens a slew of security vulnerability opportunities. Such vulnerabilities can be completely closed if the contents of the byte stream are constrained to only allow the data necessary to construct an object with that data.
The heterogeneous data model led to the creation of a keyword, transient, to delineate fields that should not be serialized. Retrospectively, this could’ve signaled an underlying problem in the approach. Additional keywords in a programming language create both a technical burden on compiler writers and a conceptual burden on learners/users of the language. The presence of the keyword implicitly encourages class designers that mixing data with runtime state in a single object is expected and desirable. Time and experience has shown the opposite, as codified in Fowler’s First Law of Distributed Object Design: Don't’ Distribute Your Objects. Had the serialization framework adopted a model such as Goetz supposes in his talk– that “people share data, not programs”-- transient would’ve been unnecessary.
Gson
Despite a 249 KB JAR file, basic usage of Gson is pretty straightforward. While some advanced options can be set– either on the com.google.Gson object itself or through a com.google.GsonBuilder to build the object– most of the important work only involves one class. In the performance testing project I produce the following “minimum viable sample.”
The following class diagram built in PlantUML shows the main workhorse methods of GSON:
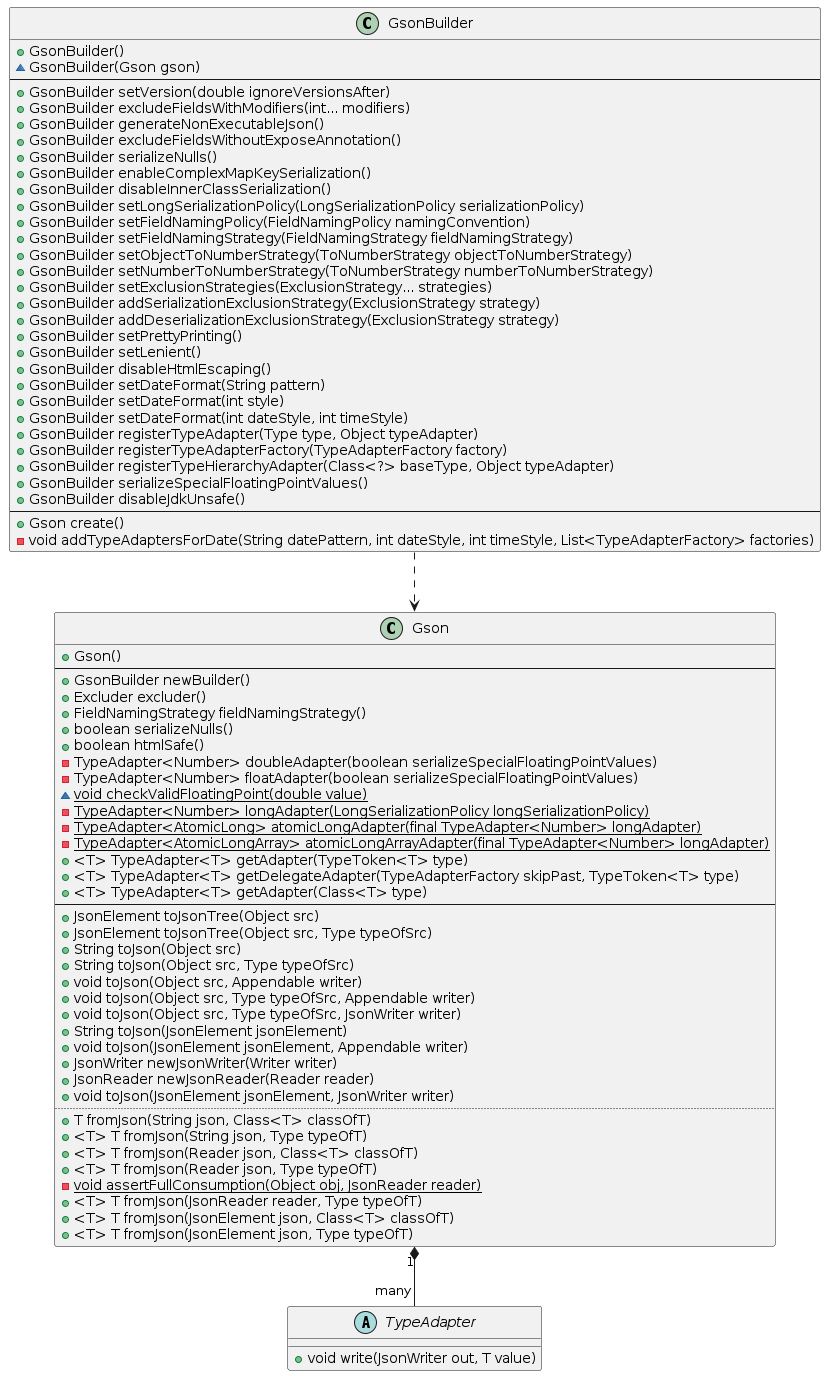
Essentially, Gson uses a com.google.gson.TypeAdapter to convert encountered types to and from JSON. Gson includes a number of built-in TypeAdapters that handle common types, while providing the possibility to overwrite adapters using the GsonBuilder. Despite the name, which is actually rather unfortunate, the TypeAdapter is not actually an implementation of ADAPTER, rather its function is more clearly mappable to STRATEGY.
Jackson
Despite a whopping 1.5 MB bundle in Maven Central, basic usage of Jackson Databind is similar to Gson and revolves around a single class, com.fasterxml.jackson.databind.ObjectMapper.
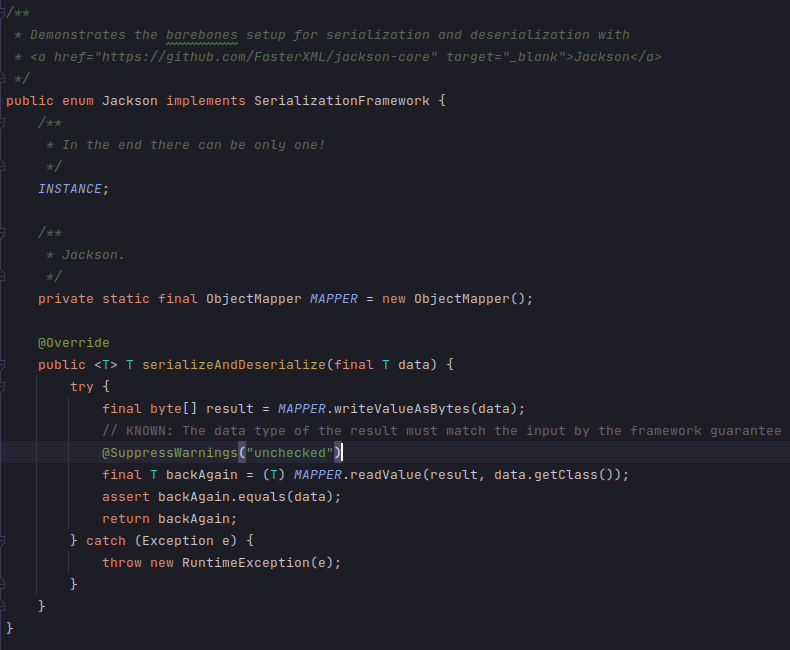
While usage seems simple, the internals are anything but. The GOD CLASS com.fasterxml.jackson.databind.ObjectMapper in Jackson's BIG BALL OF MUD architecture are significantly more complicated than anything in Gson or Java IO. The following UML Class diagram shows most, but not all, of the major components used by com.fasterxml.jackson.databind.ObjectMapper in serialization and deserialization.
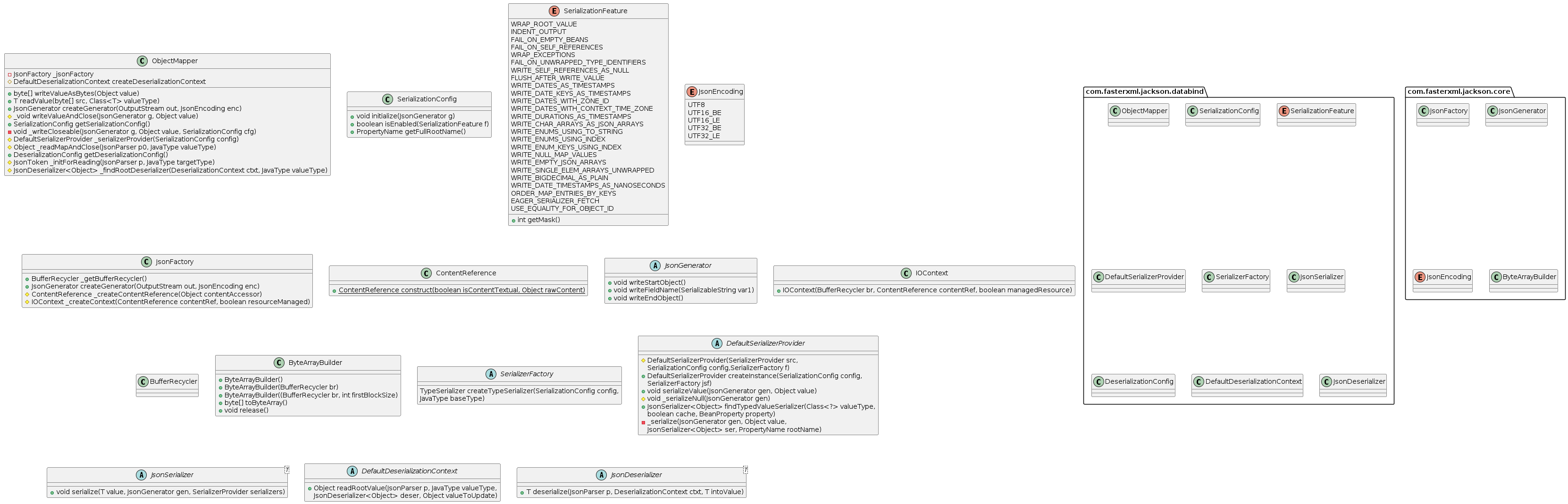
It is, quite simply, a nightmare. Beyond the usage of made-up patterns like “mutant factory”, the design shows a cascading set of abstractions. Jackson mixes large inheritance hierarchies with delegation and duplicated but slightly different design for serialization and deserialization. Despite all of these components, it essentially implements the familiar architectural pattern of having a FACADE delegate to a STRATEGY with per type selection.
Strangely, com.fasterxml.jackson.databind.ObjectMapper uses a
com.fasterxml.jackson.databind.JsonDeserializer<T> for deserialization and a com.fasterxml.jackson.databind.JsonSerializer<T> for serialization. This differentiation of interfaces is a bit bizarre. Generally serialization/deserialization are paired transformation functions. For instance, if our example Birthdate class that is serialized as an American date style string as “12/27/2022”, deserializing it as ISO8601 will inevitably result in data corruption. Deserialization must know the specific implementation details of the serialization. A more cohesive design would combine both com.fasterxml.jackson.databind.JsonSerializer<T>#serialize(T value, JsonGenerator gen, SerializerProvider serializers) and com.fasterxml.jackson.databind.JsonDeserializer<T>#deserialize(JsonParser p, DeserializationContext ctxt) into a single interface.
Johnzon
Perhaps inspired by Jackson, Johnzon’s design also features a core and mapper library. The total package size of 241 KB in Maven Central is much smaller than Jackson and quite close to Gson, but is still large enough to contain 4 CVEs found in the dependencies of 1.2.17. Basic usage follows a similar pattern, with a class called com.apache.johnzon.mapper.Mapper
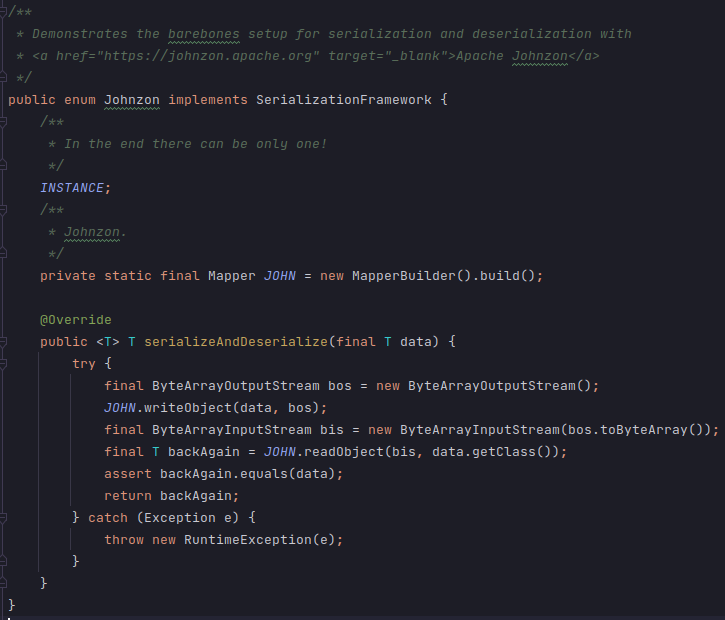
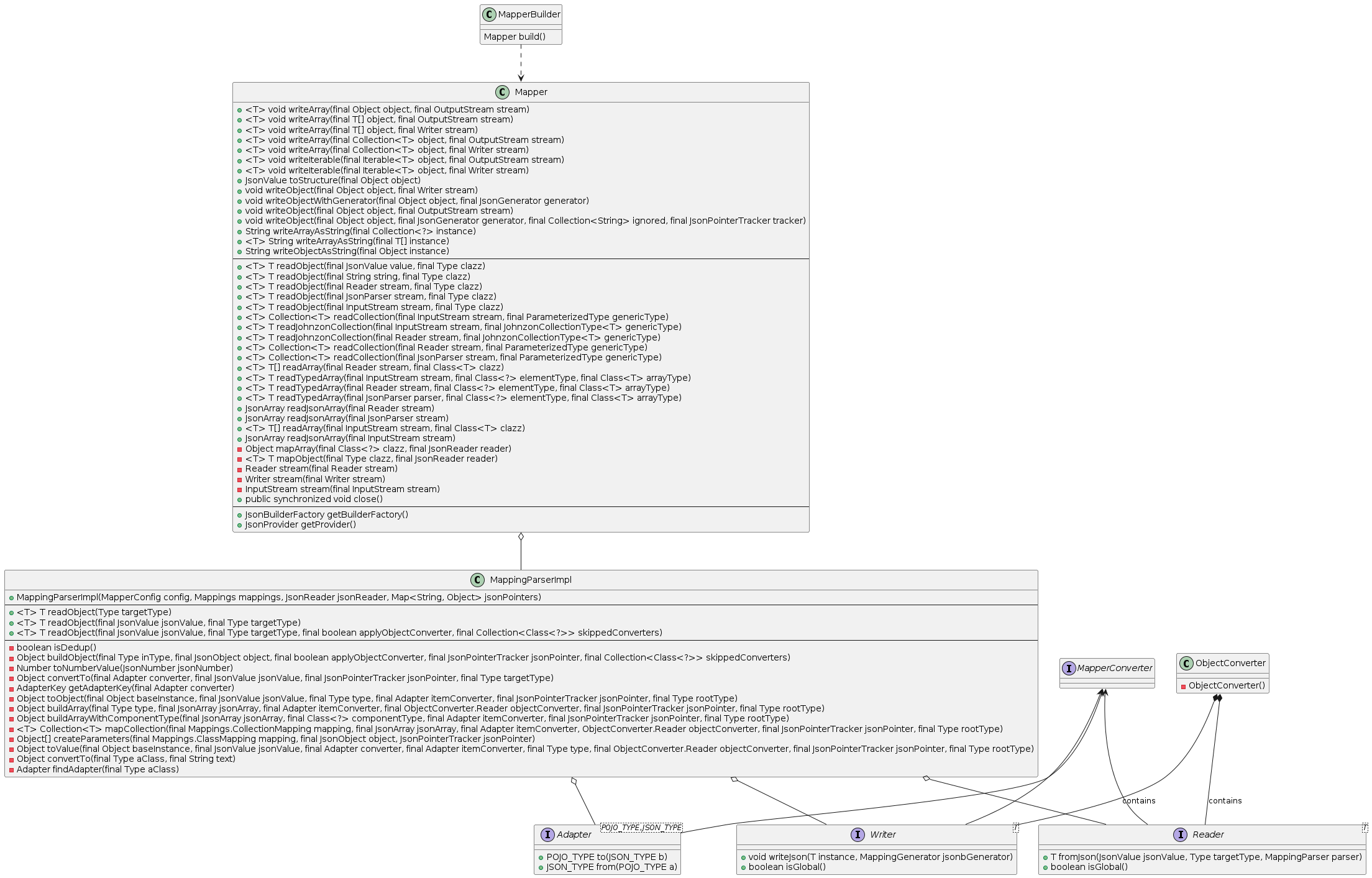
The internal structure of Johnzon is more complicated than Gson, but fragments its design significantly less than Jackson. Like Gson it offers a BUILDER to construct its FACADE with various options. It also follows the pattern all 3 share the FACADE delegating to a STRATEGY, though it contains some additional complexity by supporting referencing counting and offering an ADAPTER layer to convert DOMAIN OBJECT into DATA TRANSFER OBJECT.
Kryo
With a 348 KB Maven Central bundle, Kryo is larger than Gson and Johnzon but smaller than Jackson. Its usage is reminiscent of the others, though it has an additional step of requiring the registration of classes before use. An example follows.
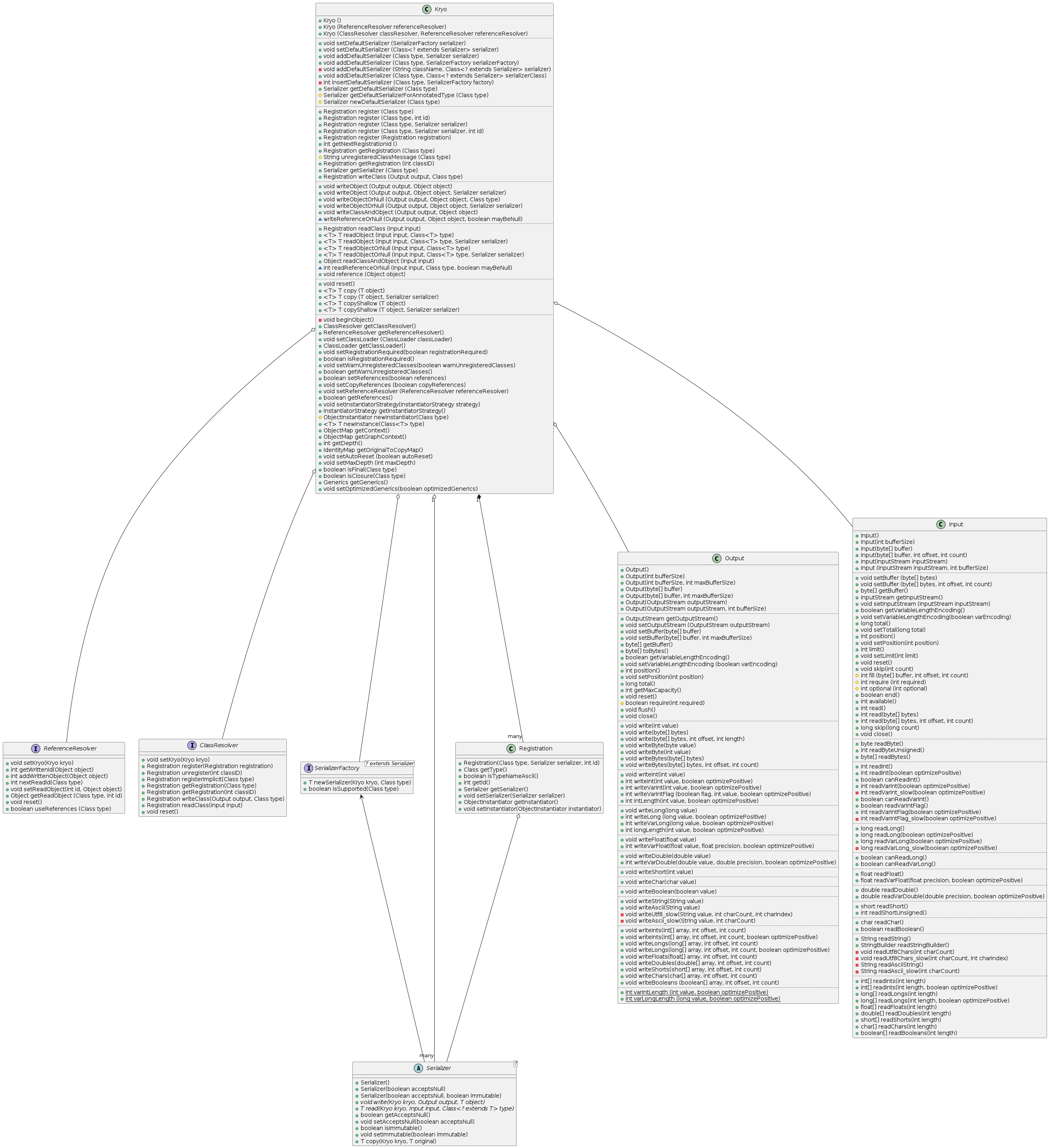
Registration allows for a prioritized and mutable list of com.esotericsoftware.kryo.Serializer to be registered for customizable serialization. Basically, as seen in every library analyzed except Java’s original IO, this follows the same FACADE and STRATEGY architectural flow. One striking thing about Kryo is that almost everything has been engineered from the ground up, with a high emphasis on performance. Classes like com.esotericsoftware.kryo.util.ObjectMap use interesting algorithms like Fibonacci Hashing to achieve impressive performance gains. Classes like com.esotericsoftware.kryo.io.Input/com.esotericsoftware.kryo.io.Output offer efficiency methods that can read/write integers/longs with variable length to optimize certain uses. While there are areas for improvement, as with any code, Kryo overall offers a more cohesive, minimal, and comprehensible architecture than most other offerings.
Discussion
This section is admittedly the hardest to write from a “purely objective” perspective. Reducing architectural comparison to some mere metrics such as “number of interfaces/classes” or “number of methods per class” loses a sense of the feelings a reader gets when pouring over the code. Gson’s use of Gafter’s Gadget extensively to deal with the problem of Java generic type erasure is clever and interesting. Johnzon’s well-designed APIs that feature uses of java.lang.Type instead of java.lang.Class show good adherence to the design principle of programming to an interface instead of an implementation. Jackson aptly displays the perils of how a seemingly simple design can explode in complexity upon wide adoption and feature requests. Kryo shows an impressive commitment to building necessary abstractions for performance and clarity from the ground up. Java IO shows a different approach–using inheritance and instances instead of a FACADE and STRATEGY.
Given the ubiquity of the FACADE/STRATEGY approach, it seems reasonable that a well-designed Anti-Corruption Layer could indeed facilitate swapping of serialization technologies similar to an ORM or an API such as JDBC. Developing an slf4j-like bridge API for serialization likely involves a way of marking objects for participation in the framework, defining STRATEGY implementations for those objects, and then implementing some kind of wiring mechanism to connect those STRATEGY into a FACADE. Exploring this idea of a common API will be the topic of a subsequent piece.
It is worth mentioning that almost every serialization library inspected has some notion of the complected and problematic elements Marks and Goetz mentioned in their talk– object graph construction/walking, back-referencing, and versioning. Should they? While these features are commonly considered part of serialization, it is worth questioning these assumptions.
Object Graphs and Back References
Accepting the view that full object graph serialization–essentially encoding data as well as runtime state– is difficult to do well and dangerous from a security perspective, invites adopting the modern conventional wisdom that programs are more interested in passing data between JVMs–with their own objects that process them– than fully RMI/CORBA approaches–with full object remoting where multiple distributed objects attempt to coordinate state change across different JVMs in lock-step. Data as just “values” as promoted by Rich Hickey in his talk “the Value of Values” allows use of modern JVM constructs such as Records which can easily be cached and efficiently constructed thanks to their immutability and well-defined interoperability semantics. Hence, while it is possible to apply a back-referencing scheme to detect duplicate objects and optimize their byte representation, I view that as a non-essential requirement of a serialization framework.
Versioning
Versioning deserves special mention because it is arguable that even trying to manage it in a typical programming workflow is wrong. The problem with versioning is that code itself is mutable. Any versioning technique will have to handle an impedance mismatch between code as it currently appears and code as it was previously serialized. Java IO tries to handle this with fields like serialVersionId and serialPersistentFields that programmers are supposed to manually mutate when incompatible changes are made, along with adding code in an ad hoc manner to a changed class to handle its previous versions. The difficulty and inconsistency in doing this results in many pervasive bugs across software.
An instructive and interesting approach to this problem can be found in the Amazon AWS SDK for DynamoDB in Java. In contrast with many libraries, the DynamoDB SDK explicitly duplicated structures when moving from version 1 of their API to version 2, using different packages to denote the versions. While at first glance this results in a massive amount of code duplication–which feels like a Code Smell– it does enable a clean versioning solution.
Rather than maintaining deprecated constructors/methods in a continually evolving class, developers can mark the old class as deprecated, implement an ADAPTER from the old class to the new, and use the new class everywhere in the system. Eventually when the system completely phases out the original object, developers can delete the corresponding class and ADAPTER.
An evolved approach towards this problem would codify such a workflow and perhaps even integrate it into the compiler. A compiler with a history of its compilations or integration into a source control system could do a lot to help manage versioning. Once a type has been identified as something where previous versions are known and important–such as existing in serialized forms or used within the internals of frameworks– its structure should be set as “immutable”--such as the file becoming read-only and any attempts to modify it resulting in compiler errors unless done in a privileged way. Desired mutations to such a structure should be expressed through a specially crafted Domain Specific Language to define transformations to the type – such as “remove a field”, “change the type/name of a field”, “add a parameter to a method”, etc. With such tooling, the compiler could generate versioned objects and ADAPTERs between versions synthetically.
Such an approach is basically used in database migration tools such as LiquiBase which perform database schema versioning. I argue that is essentially the same problem as serialized object versioning. Consequently, dealing with versioning may not actually be a “sub-feature” that a serialization library needs to manage itself. It may actually be a separate feature/library that handles versioning in a way that serialization is compatible with and respects.
Conclusion
We've explored the architecture of various serialization offerings. Java IO has a small public surface area, though larger than expected complexity in the innards of java.io.ObjectOutputStream/ObjectInputStream. Gson has a relatively straightforward architecture. Jackson's architecture is massive and fragmented, with a lot of moving parts that obscure a relatively simple fundamental pattern. Johnzon's architecture is a bit slimmer, using modern API design techniques. Kryo features abstractions built from the ground up that focus on performance. While Kryo doesn't rely as much on JDK standards, it does offer a small, understandable surface area of functionality. All of these architectures can be summarized as variations of a basic combination of usage of the FACADE and STRATEGY patterns. This common kernel suggests a uniform API, which I explore next.