
Get the code from Bitbucket. If you find this useful, donate to the cause.
Results of Best Practice Performance Comparison for Java Serialization libraries
By Nico Vaidyanathan Hidalgo
Question 1: How does the number of instances affect serialization framework performance?
One might naively expect that the throughput of a serialization framework would scale linearly with the number of instances to be serialized per second. That is, the throughput at 1000 objects/second would be an order of magnitude less than the throughput at 100 objects/second. This assumption is worth testing.
For one, it is possible for serialization frameworks to use advanced techniques to short-circuit the serialization process, such as caching or entropy encoding. The idea is most obvious for the single boolean field object case: a fair random distribution of 1M objects would have approximately 500K true and 500K false. If the framework were to internally store serialization results by object hashcode and pre-calculate it before delegating to a serialization STRATEGY, it could trade-off more in process memory usage to avoid duplicating work when seeing the same object repeatedly. It could return the pre-calculated byte array or some kind of special symbol that it internally maps to the corresponding bytes and can restore them on deserialization–reducing payload sizes.
For another point, it’s worth checking if serialization frameworks use parallelism internally. If they do, the throughput change may not exactly be linear. Is parallelism a good option for serialization frameworks? Intuition says yes. A serialization framework that only serializes— only converts objects to bytes and doesn’t directly write those bytes anywhere– performs CPU bound work, not IO bound. Moreover, each object can be seen as a list of fields to be converted to bytes. If those fields are independent–such as the value of a Person’s name does not depend on their favorite color and vice-versa– then serialization as a function maps cleanly to a Map/Reduce. Each field can be serialized in parallel and then combined into a resulting byte array. If the serialization framework knows the index range for each serialized field, it can also deserialize by splitting the input byte array into N input byte arrays, deserializing the field values, then constructing the object with the fields.
Both of these approaches are admittedly theoretical and require more work to implement than a standard FACADE/STRATEGY delegation. It is also possible that the overhead of caching/compression/parallelism actually diminishes performance for the average case. But seeing as serialization is a well-understood problem and many of these libraries have been around for multiple decades, I wondered if I might find something like this in “battle-tested libraries.” The results are shown below.
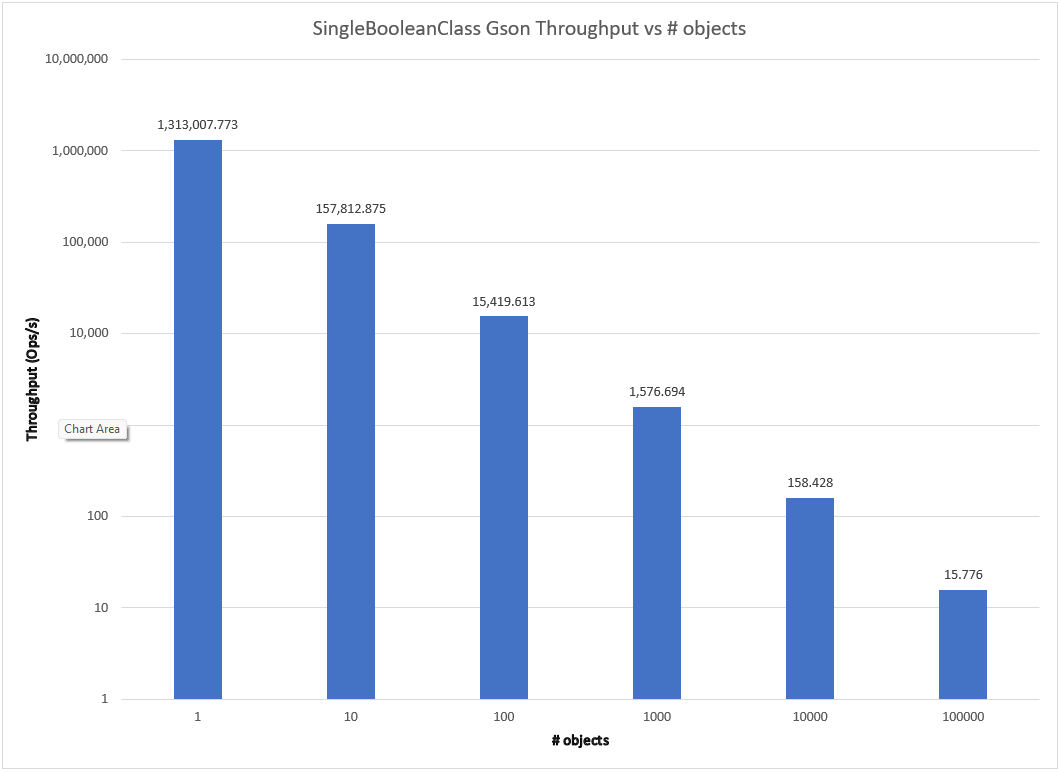
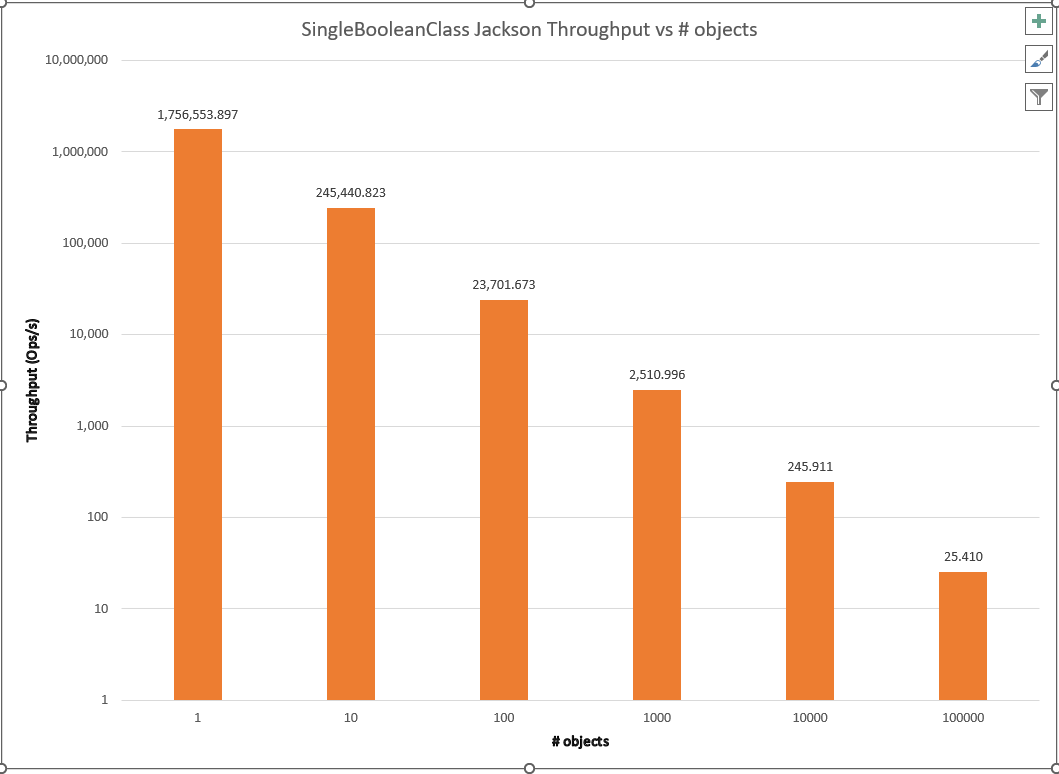
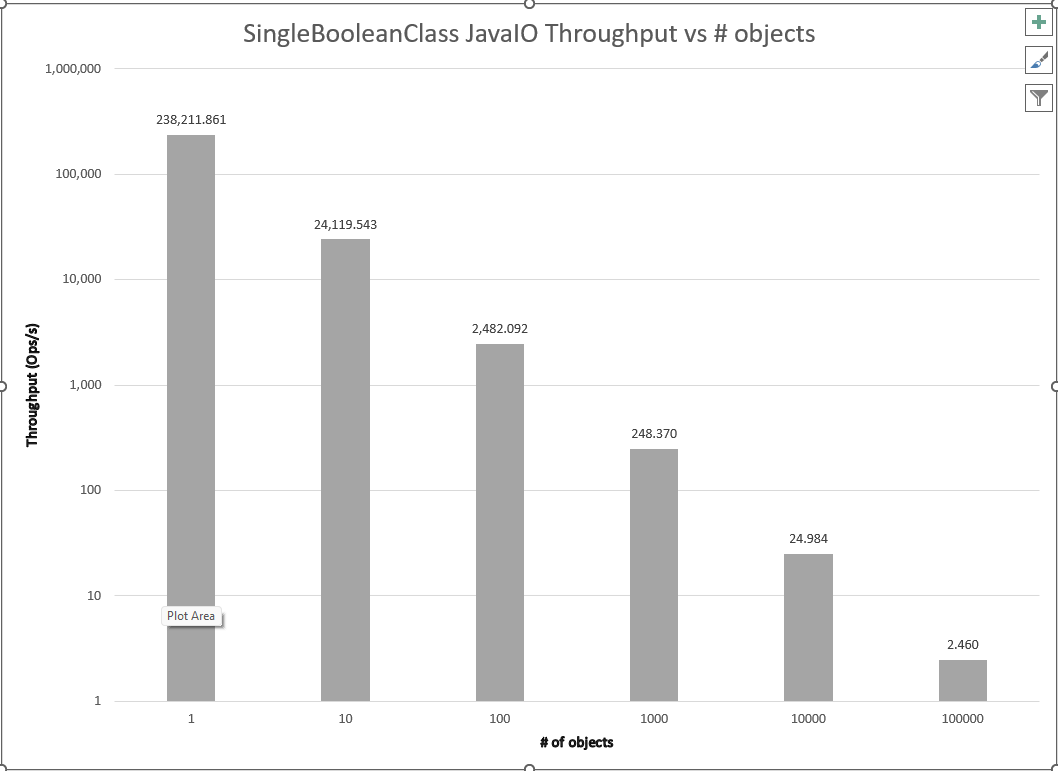
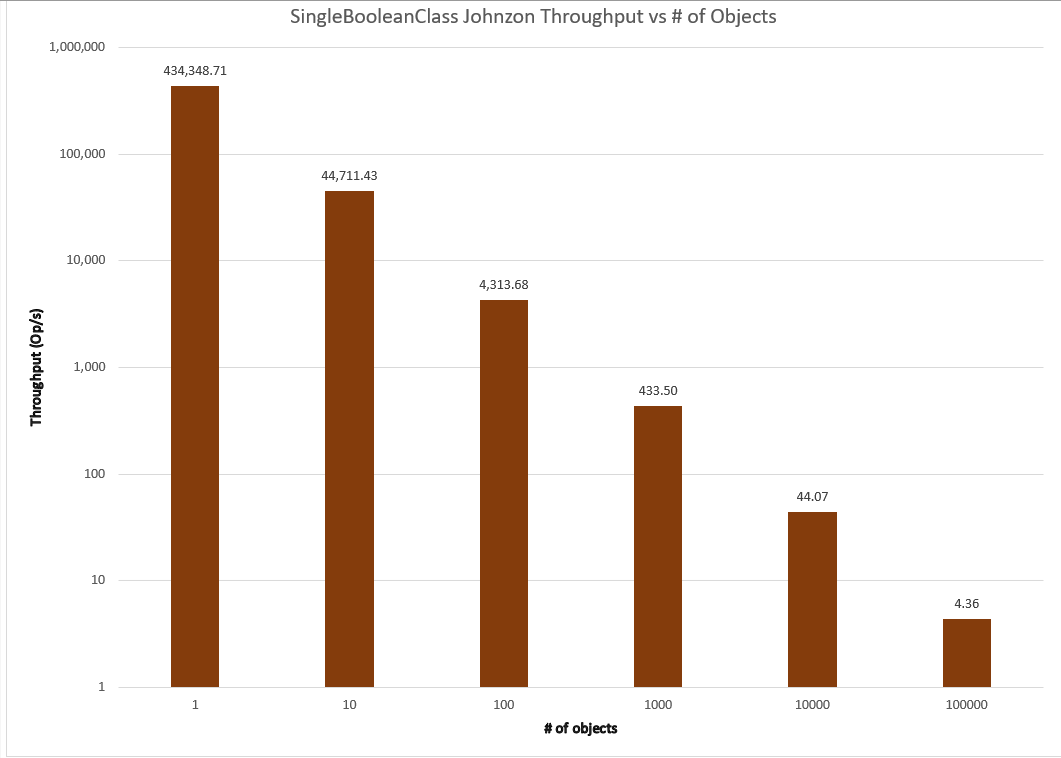
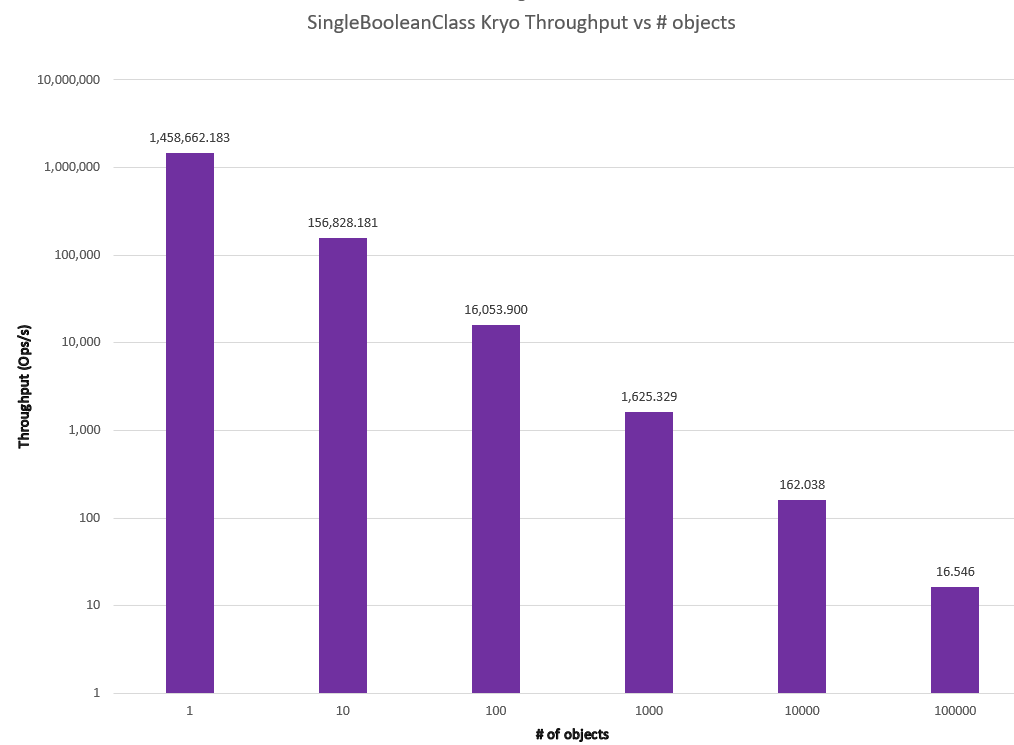
As we can see, all of the libraries examined exhibit the expected order of magnitude decrease in throughput. Have the proposed algorithms been tried and rejected? Impossible to say without both diving into the commit history and interviews to harvest tribal knowledge about conversations that never resulted in code.
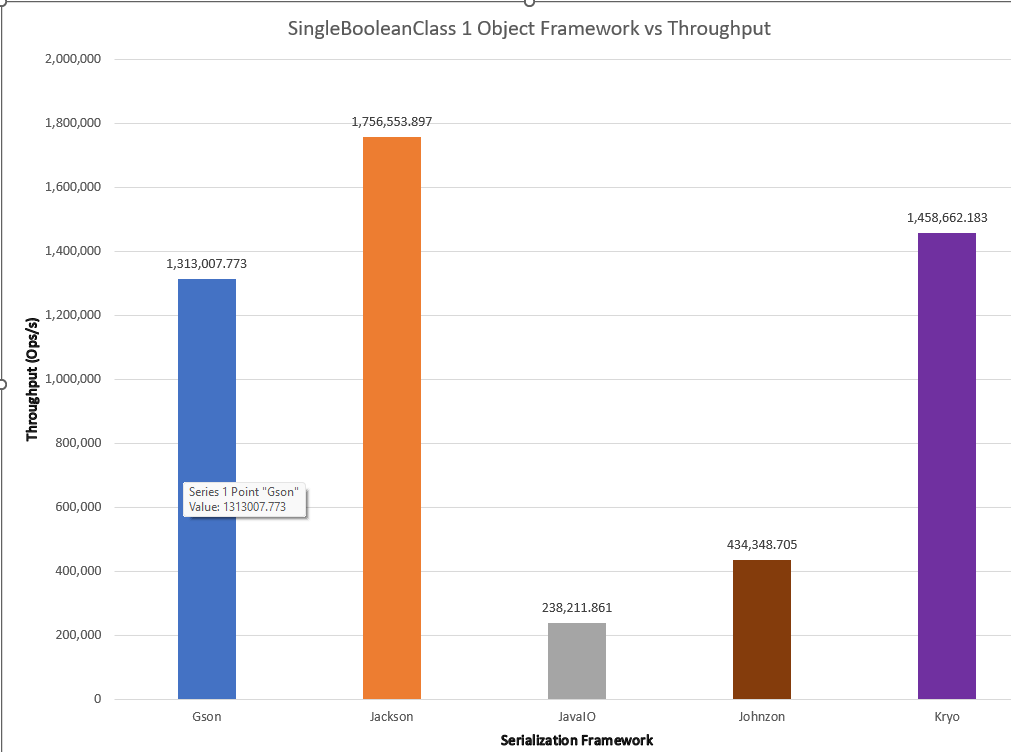
One convenient outcome is that this result simplifies further comparison. The standard relationship between throughput and number of instances makes it reasonable to set the number of instances as a fixed constant for these libraries and compare them for throughput and memory usage/garbage collection for the different classes. While many simplistic benchmarks do this as an assumption, a rigorous scientific and engineering approach tests, measures, and provides support for such an assumption rather than taking it by fiat. A side-by-side comparison of all the frameworks for the SingleBooleanClass at 1 instance is shown below.
Question 2: How does the number of fields affect serialization?
A straightforward way of testing the effect of the number of fields in an object on serialization is to examine the differences between serializing instances of n = {1, 2,3,…} number of fields of the same type. Examples are shown below:
One might expect a linear rise, similar to the number of instances. It is possible, however, that a framework may apply some cleverness in a STRATEGY. I can think of a couple of ideas.
For instance, consider the TwoBooleanClass and ThreeBooleanClass. A simple STRATEGY implementation might take the straightforward approach of mapping a boolean directly to a byte. So TwoBooleanClass would need 2 bytes and ThreeBooleanClass would need 3 bytes.
A clever framework might count the number of boolean fields an object has and use bytes = ⅛(numBooleans). After all, the smallest representation of a boolean is a bit. Then a CleverSerializationStrategy may choose either Big Endian or Small Endian representation and fill each byte with the bit value of the boolean. So, in Big Endian, TwoBooleanClass could use {0000,0001,0010,0011} and ThreeBooleanClass could use {0000,0001,0010,0011, 0100, 0101, 0110}, using 1 byte but encoding the object state in it.
This works for a variety of data types. Enums can have the same caveat applied, saving a lot of bytes. Even types more difficult to map as cleanly can have a similar algorithm applied. Classes that represent multiple fields in the domain model with integers that have values less than Byte.MAX_VALUE or Short.MAX_VALUE can downcast or combine multiple values in 1 int by encoding.
A STRATEGY using reflection might use parallelism. The algorithm is similar to the multiple objects description, simply serializing each field in parallel and concatenating the result. Such an approach would likely be slower for reasonably sized objects. But pathologically sized objects can show a remarkable improvement. In a team of Customer Service Technology at Amazon, I worked directly on a web service that did sentiment analysis on a customer profile with over 100 fields. One of our biggest performance improvements came when we started propagating and serializing snapshot fields in parallel.
A comparison of the serialization frameworks throughput for 1000 objects is shown below:
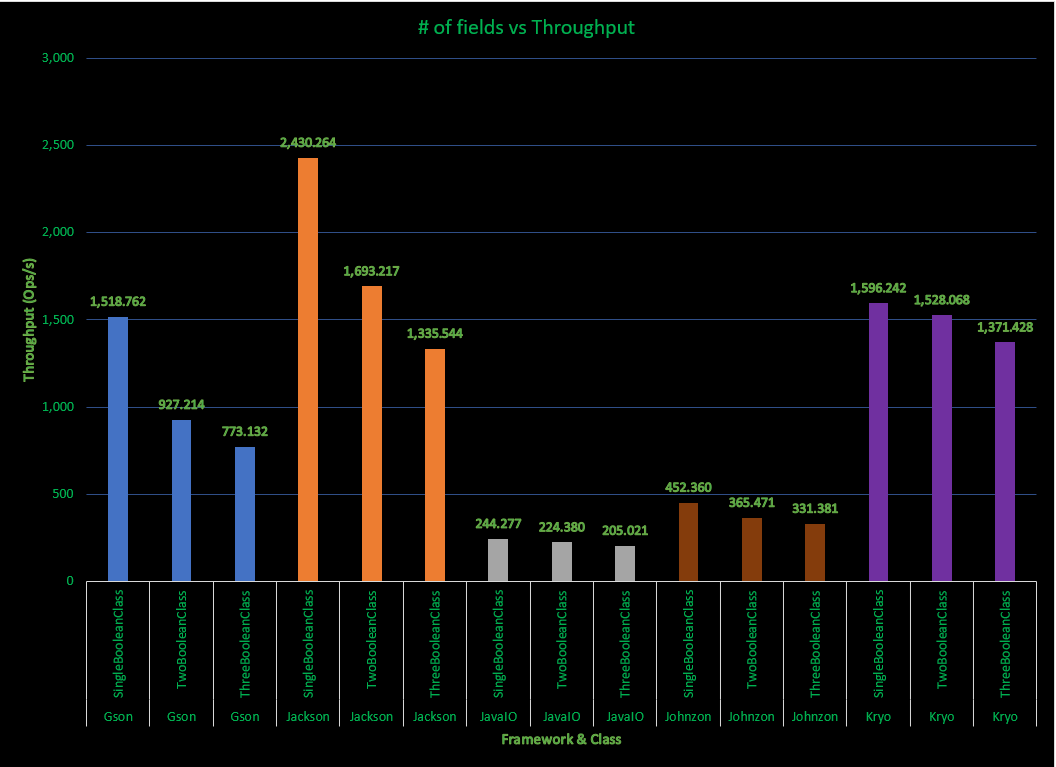
These results are fairly interesting. Java shows a remarkably consistent throughput across the number of fields. Why Java’s approach seems remarkably steady across the number of fields seems like a good candidate for future investigation. Jackson and Gson do remarkably well for a single boolean value, then fall dramatically. This perhaps signals that serialization has special short-circuit/cached logic for those cases. Kryo has a consistent throughput signature similar to Java, and actually surpasses Jackson by 3 fields.
Question 3: How do the various fields with different types affect object serialization?
Answering this question is essentially the point of serialization framework comparison for a system’s own object model. While synthetic generation of {OneIntegerClass, OneFloatClass, OneDoubleClass, …} and comparison with {TwoIntegerClass, TwoFloatClass, TwoDoubleClass, …} might provide some marginal utility in comparing the scaling factors between number of fields, a full cross product of primitive types across number of fields explodes the data space dramatically. It may also not necessarily be helpful for real world analysis.
I designed 3,5, and 10 field POJO classes to explore the effects of different types within an object based on what I’ve commonly encountered in object models in the wild. Rather than large pictures of mostly uninteresting code, I’ll describe them in text. ThreeFieldClass has {boolean, int, String}, FiveFieldClass has {boolean, int, String, double, java.util.Date}, TenFieldClass has {boolean, int, String, double, java.util.Date, byte, short, long, char, float}.
Varying serialization of n = {1,10,100,1000,10000} objects for these frameworks, I obtain the results below.
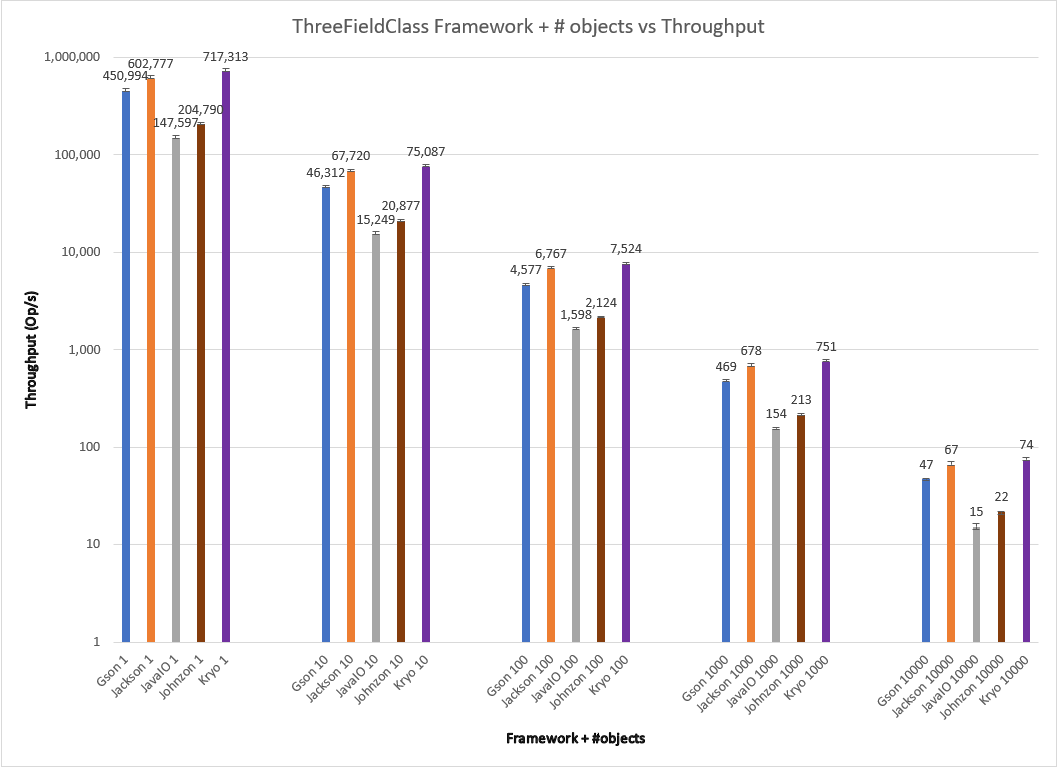
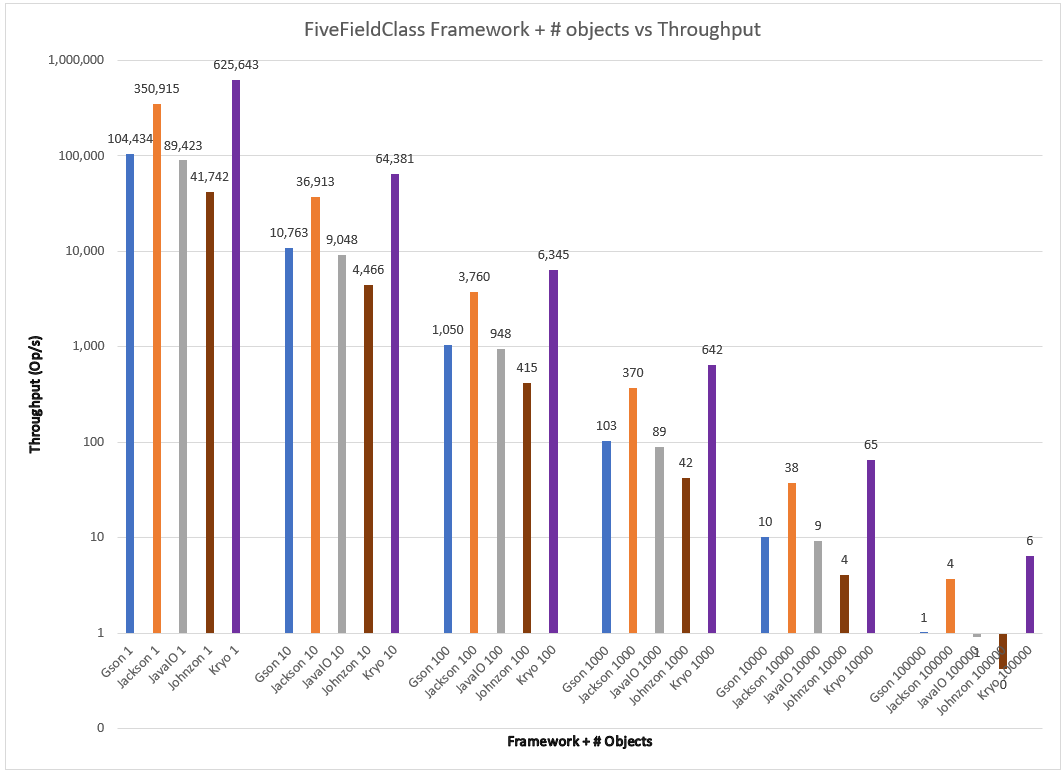
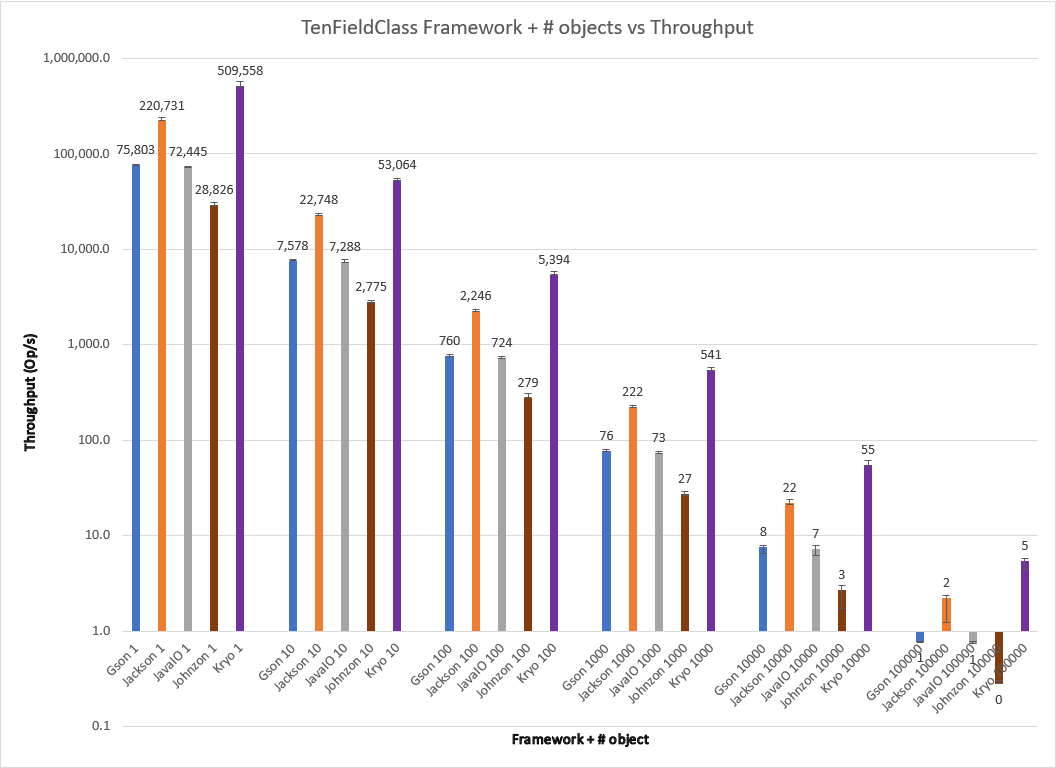
The results show the trend that began to happen with ThreeBooleanClass to a pretty dramatic effect. Kryo offers dramatically more throughput than Jackson as the number of fields grows; the difference between them continues to grow. For TenFieldClass Kryo offers more than 2x throughput for all test conditions. Gson’s default serialization performs pretty competitively despite its simplistic approach. Johnzon, despite the seeming cleanliness of the code, struggles slowly in all cases with its default serialization for FiveFieldClass and TenFieldClass, losing even to Java in all cases.
Question 4: How does immutability affect object serialization?
Quite a bit, as only Java IO offers by default immutable object serialization. The other frameworks by default only support field scraping reflective approaches that cannot populate constructors with parameters. A simple immutable SingleBooleanClass following Joshua Bloch’s rules for immutability in Effective Java is shown below:
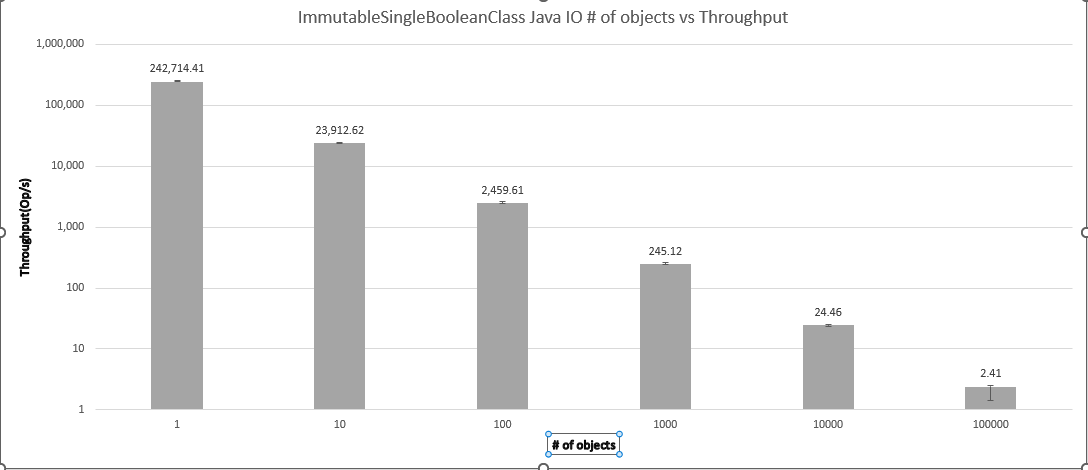
An astute reader will notice this is essentially the same as the Java IO graphs for number of objects. The results are essentially the same for it whether an object is mutable or immutable. This may be surprising.
What about Records?
It is interesting to note that Oracle claims simpler and faster object serialization for Records, which are immutable. Putting that claim to the test is fairly easy with this benchmark. After generating Record versions of the SingleBooleanClass and ThreeFieldClass, I generated the following results:
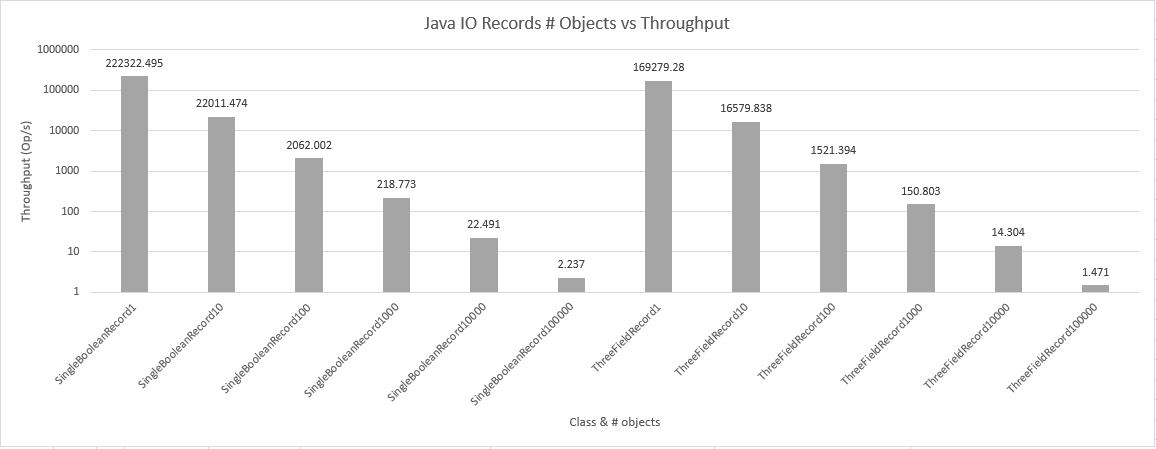
Accounting for the error rate reported by JMH, the results for ThreeFieldClass and ThreeFieldRecord are approximately equivalent. Perhaps future versions of Java will change this.
Question 5: How does Garbage Collection affect object serialization?
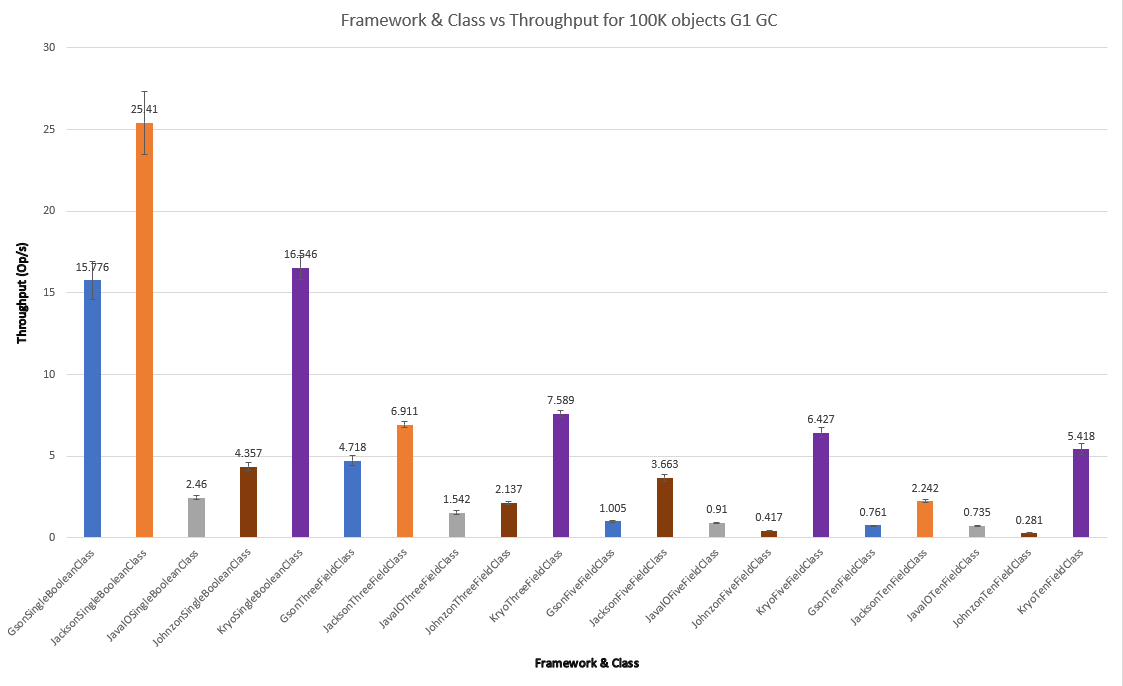
For the sake of review, here’s a different view of the classes with different fields for 100K objects on the G1 garbage collector:
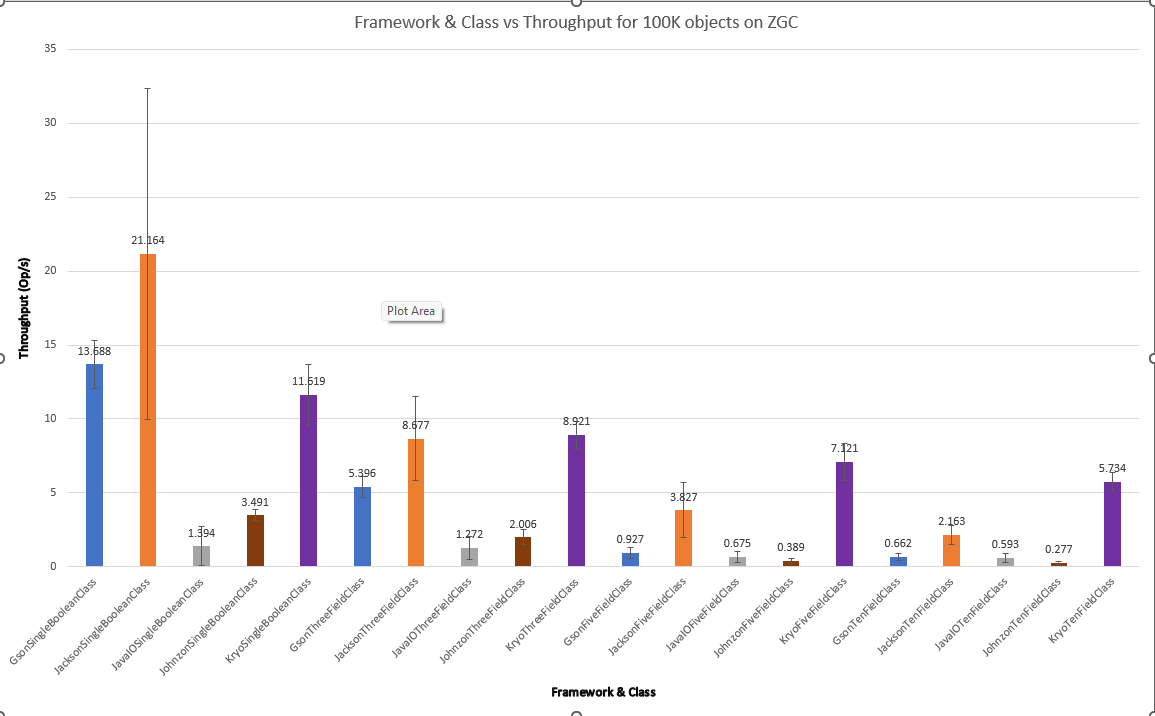
With ZGC yields the below results:
With Shenandoah yields the below results:
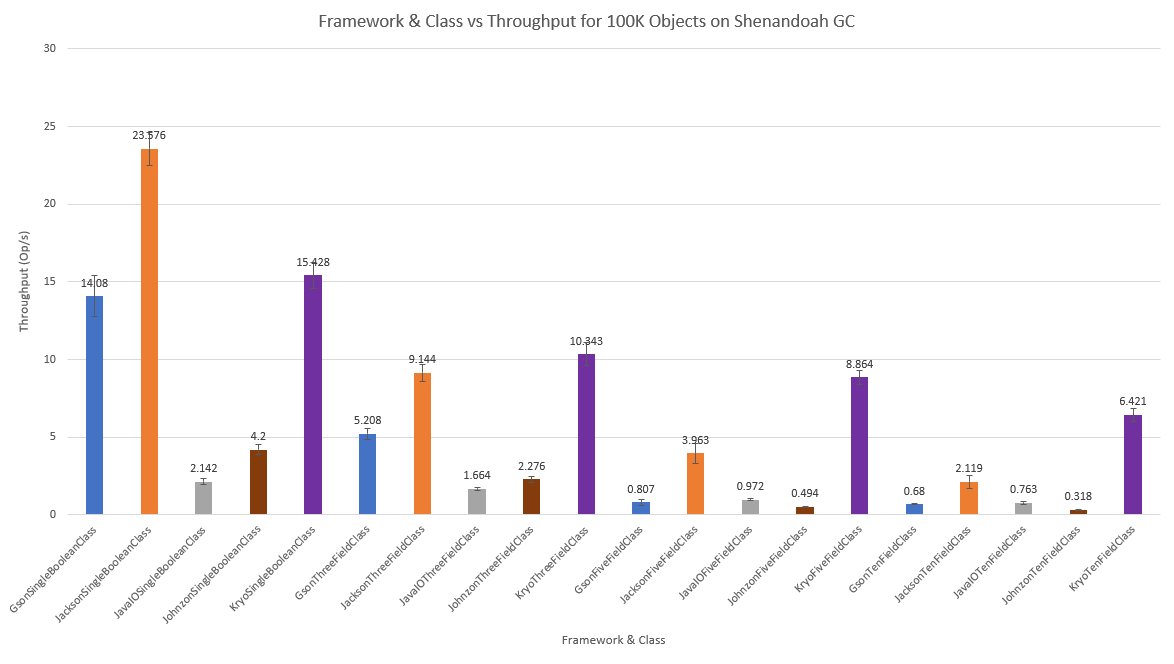
For less work, such as the SingleBooleanClass, G1 performs slightly better. As the work to be done increases, like for FiveFieldClass and TenFieldClass, Shenandoah and ZGC seem to help a little more. It’s interesting to note that ZGC seems to have larger error bars, leading to more variance in throughput across GCs, while Shenandoah’s algorithm seems to be generally more consistent across the workload. That said, all of the throughput scores with error bars are well within an order of magnitude, so changing the garbage collection algorithm doesn’t dramatically affect the performance of these frameworks.
Conclusion
In the absence of a satisfactory general purpose serialization framework comparison benchmark, I developed one. Using the benchmark, I explored the effects of the number of objects, number of fields, heterogeneous types of fields, mutability, and garbage collection for the popular serialization frameworks Java IO, Gson, Jackson, Johnzon, and Kryo. I find that the number of instances more or less correlates with a linear drop off in throughput for all of the frameworks. The number of fields has a similar drop off in most cases, but Java IO does something different that leaves it less affected, Kryo is also fairly steady in this regard. When subjected to more complex objects, once again Kryo and Jackson lead the pack, with Gson generally in the middle while Johnzon and JavaIO are generally lagging. Immutability may someday have an impact, but currently there’s no evidence that it affects serialization at all. The choice of garbage collection algorithm–with default settings and no additional tuning– might make a modest impact, but will not dramatically affect throughput in most cases. A fair caveat in all of this analysis–I have purposefully chosen default settings and barebones usage for all frameworks and garbage collection algorithms. It is perfectly possible that using custom Kryo Serializers or choosing one of Jackson’s different encoding formats like CBOR or Smile may change results. Optimal tweaking of GC parameters may reveal a far greater difference. But in my blunt opinion, across the hundreds of software projects I’ve worked on, it’s rare to see anything but the bare minimum. Many work by taking a serialization framework and using it in the absolute easiest way to begin with. A wide variety of projects in the wild never dig into the weeds to wring every last bit of performance out of the framework.
Using this methodology and approach, I am curious if I am able to write a unifying API–a sort of “serialize4j” like slf4j– and if I am able to write a leaner, higher quality, and faster library than these options for serialization. In future work, I explore this theme.