
Leanness and Code Quality of Java Serialization Frameworks
Running SCC & SonarQube on selections
By Nico Vaidyanathan Hidalgo
During part 1 of this series, I defined fast, lean, and high quality as the primarily desired traits for object serialization. This article dives into leanness. Mary & Tom Poppendieck's Lean Software Development inspired a lot of my thinking in this regard.
Leanness is important for improving security, performance, and comprehensibility. I evaluate the leanness of the selected libraries by comparing the size of their code-bases in terms of lines of code, number of classes/abstractions, and dependency footprint. Generally the minimum necessary is preferred, but it’s worth noting a few important caveats. Less lines of code is not always better. Fewer lines might be defect-dense or difficult to understand. Similarly, fewer classes/abstractions are not necessarily superior. Fewer classes may signal a lack of separation between interface and implementation or yield repeated instances of GOD CLASS/BIG BALL OF MUD.
I count lines of code and classes with SCC and SonarQube. I present the results in a table and some analysis of each calculation. Finally I provide a ranked list based on my criteria for leanness.
SCC
Java IO
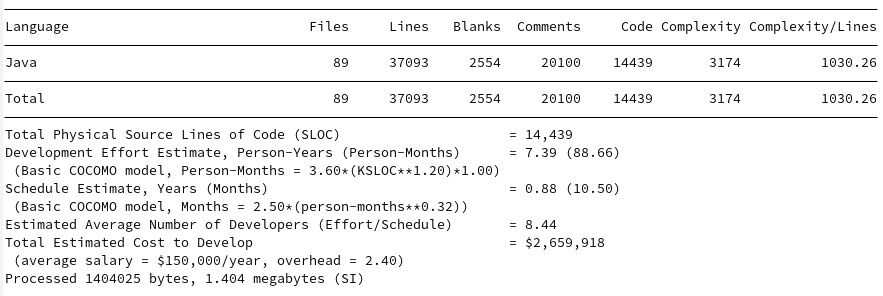
Gson
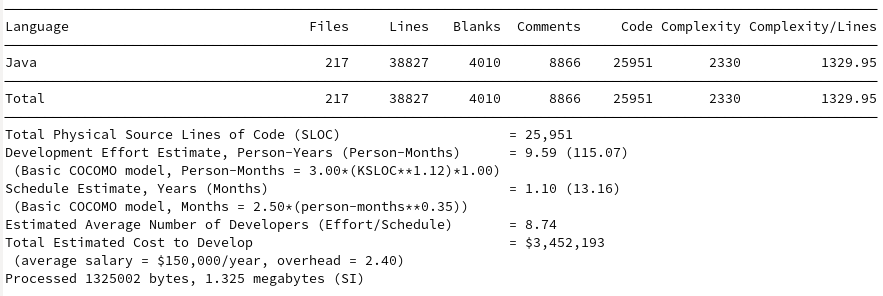
Jackson
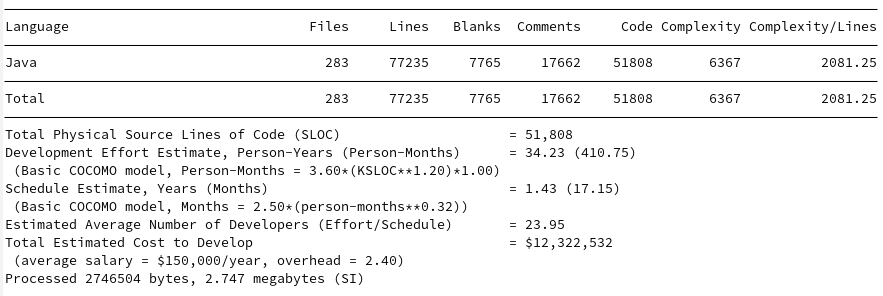
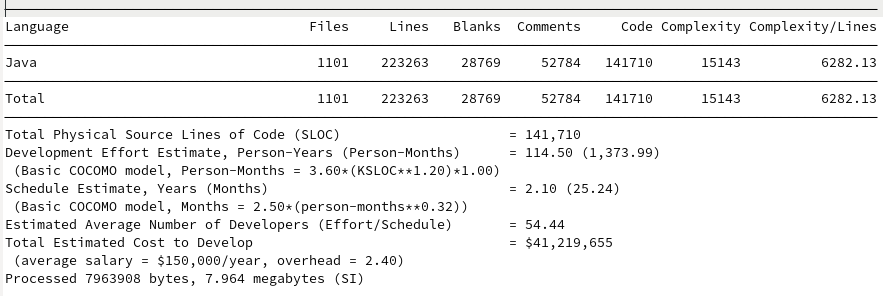
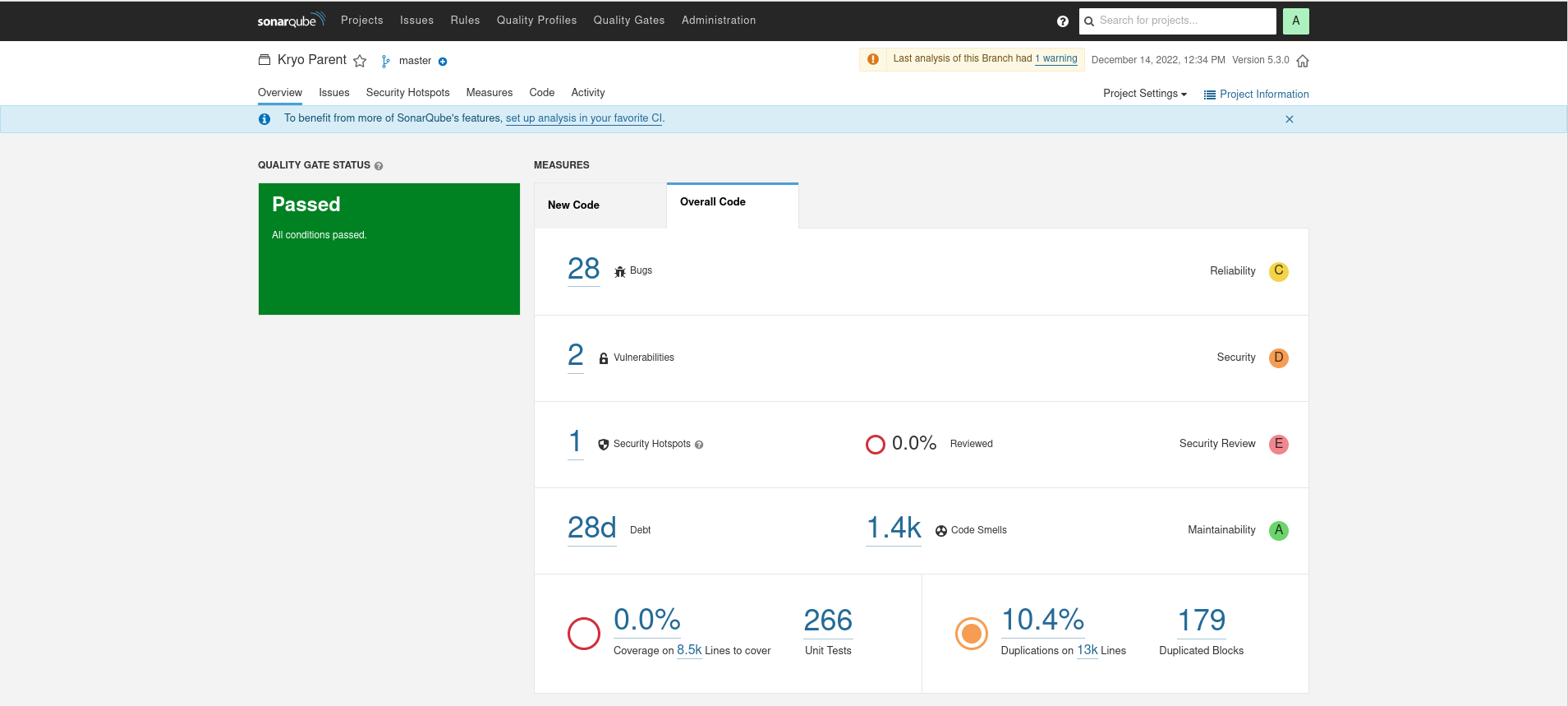
Johnzon
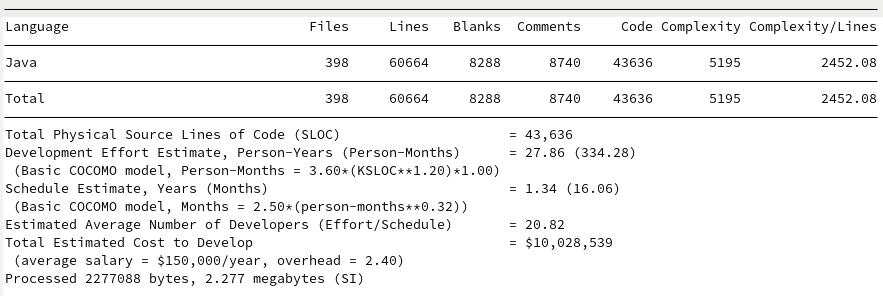
Kryo
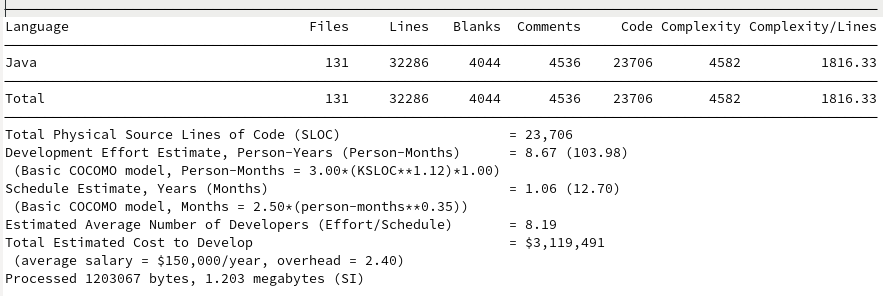
Discussion
I find the Boehm et al's COCOMO calculations interesting from my graduate work in software engineering, but honestly I don’t put much weight into them. Boehm’s work is valiant given the scope of the field, but linear regression models on 63 projects in the 1970s and 161 projects in the 1990s simply does not fill me with confidence.
The models are interesting in that they find GSON and JavaIO to be roughly the same development cost, despite estimates of GSON taking approximately 2 years more to produce 10K more lines of reduced complexity. Johnzon ranks approximately the same as Jackson despite having 7K fewer lines, both seeming to require about 20 developers and around 30 Person-Years. Kryo’s cost estimate is surprisingly cheap given its quality and performance.
For my analysis I’m more interested in grading the leanness of the projects based on their size and complexity. I want to optimize for the least number of lines of code, least number of files, and complexity per line. This leads to the following:
| Library | Lines of Code | Files | Complexity/line |
|---|---|---|---|
| Java IO | 14,439 | 89 | 1030.26 |
| Kryo | 23,706 | 131 | 1816.33 |
| Gson | 25,951 | 217 | 1329.95 |
| Johnzon | 43,636 | 398 | 2452.08 |
| Jackson (Core + Databind) | 51,808+141,710 | 283+1101 | 2081.25+6282.13 |
SonarQube
I downloaded and set up a local instance of SonarQube 9.7.1.62043 and manually instrumented each project to provide code coverage numbers using JaCoCO 0.8.8, where possible.
Java IO
I found myself simply unable to import the portion of OpenJDK containing only java.io into SonarQube. SonarQube integrates most easily with Java projects built in Gradle/Maven, the JDK itself is another matter. After some time investigating integrating it into the Makefiles and getting JCov to report coverage statistics, I gave up. I would be happy to add the JDK’s serialization analysis if someone can figure out how to instrument/import it correctly.
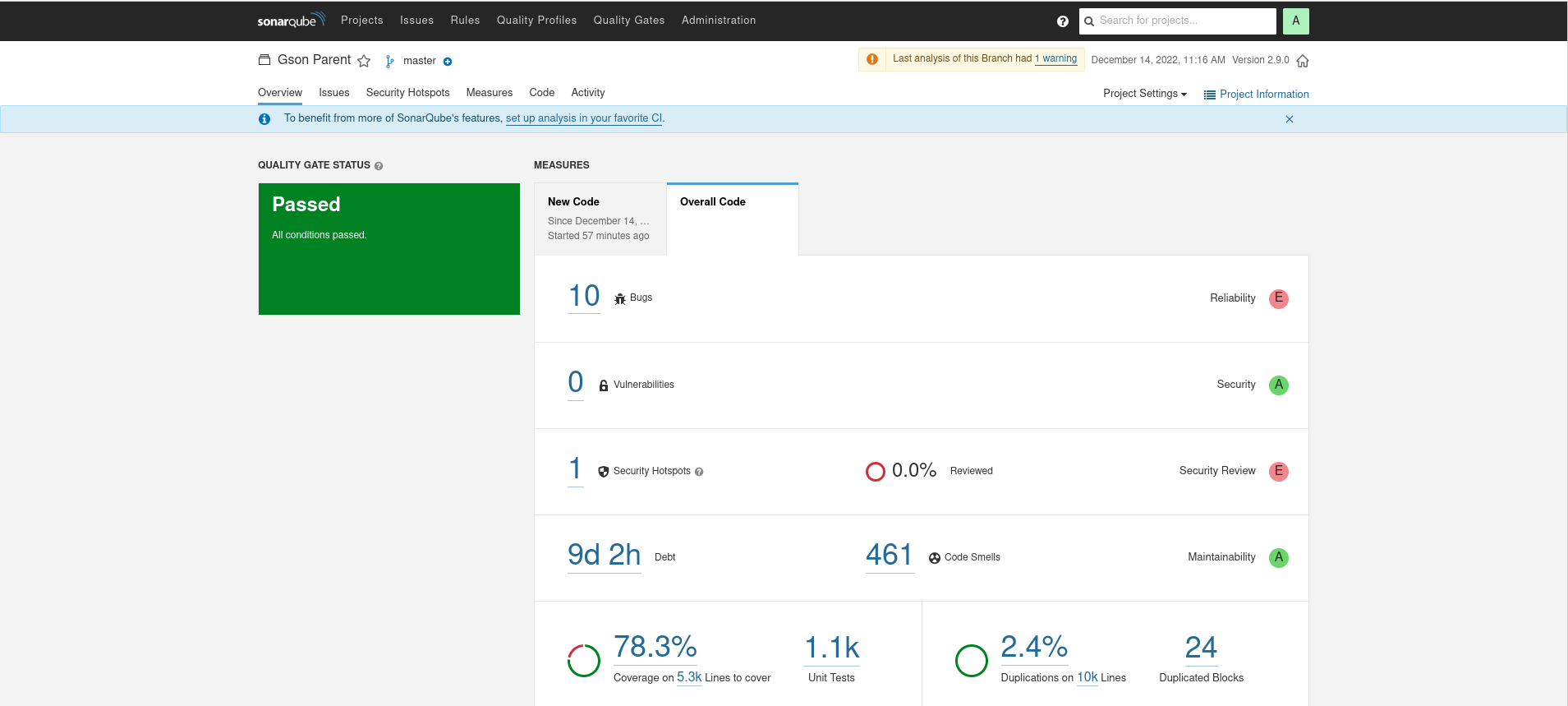
Gson
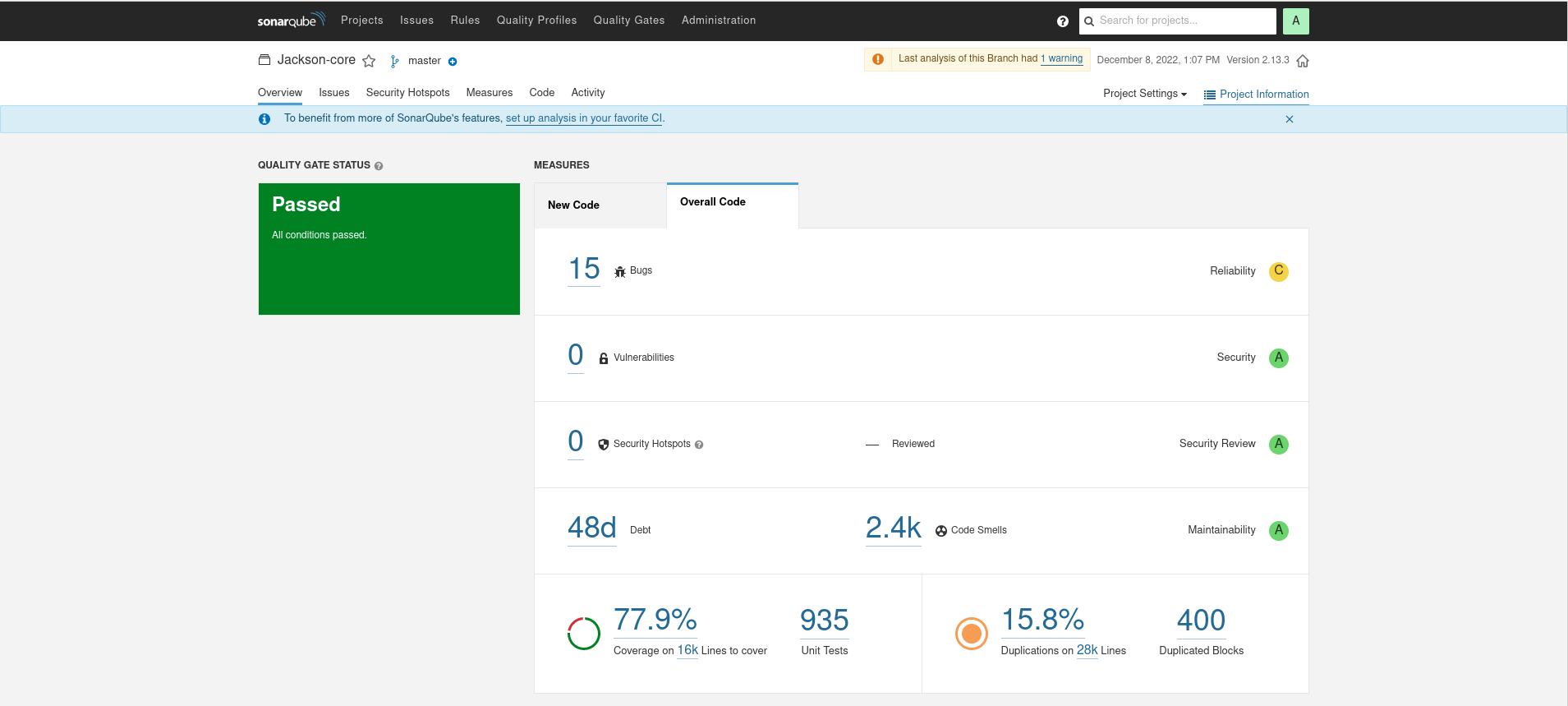
Jackson
Johnzon
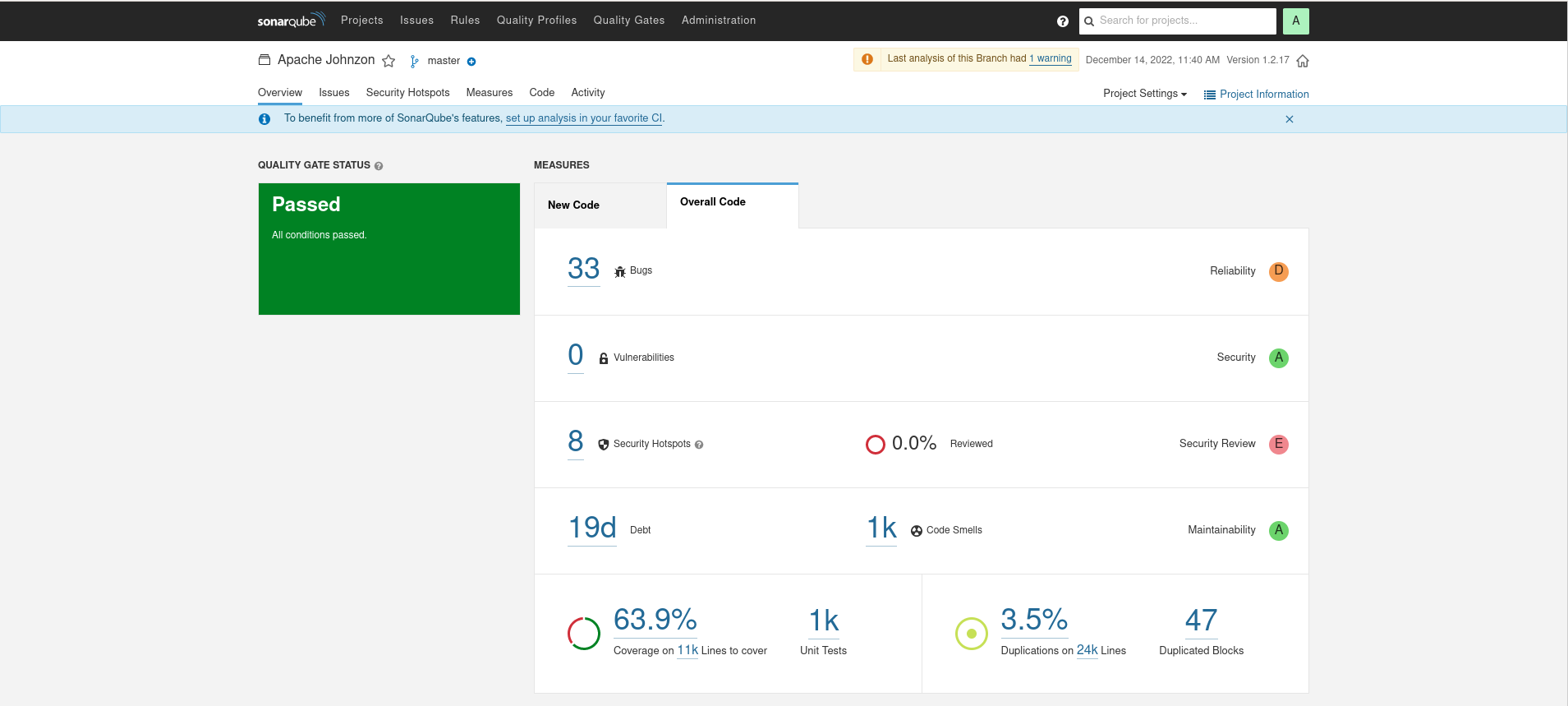
Kryo
Discussion
It is interesting to note how wildly different the source line count is between SCC and SonarQube. The counts are much lower in SonarQube, perhaps evocative of a different Java specific scheme for analyzing the source files.
SonarQube applies some pretty strong opinions on what it interprets as Bugs or Code Smells, but as these numbers can be interesting in evaluating the leanness of a library. Overall, the leanest library of highest quality would have the lowest ratio of bugs/lines, smells/lines, and minimize duplications. These are calculated below:
| Library | Bugs/lines | Smells/lines | % duplications | % coverage |
|---|---|---|---|---|
| Gson | .001 | .0461 | 2 | 78.3 |
| Jackson | .0005 | .0857 | 15.8 | 77.9 |
| Johnzon | .001 | .0416 | 3.5 | 63.9 |
| Kryo | .002 | .1076 | 10 | ?? |
Where do we go from here?
Static code analysis tools can give us a rough idea of the leanness of software and initial impressions of the code quality, but as Grady Booch often repeated in his On Architecture podcast, "The raw, running, naked code is The Truth." In the next piece, I dive into the architecture and discover the generalizable pattern for serialization libraries.